Tuples, Lists, and Arrays
Programmers use various data structures for arranging elements in a sequence. The simplest ones are arrays and lists. If the elements in the sequence are to be kept in order, a binary search tree may also be a good choice. In this chapter, we will focus on lists and arrays. We will also discuss tuples as a means for grouping together a constant number of values of different types. The number of elements in a list or array can be arbitrary, but they must all be of the same type.
In Haskell, lists are used much more widely than arrays, while in imperative
languages, the opposite is the case. We already defined the list type
before. Before looking at the
definition of the Array type and discussing standard operations we can perform
on lists and arrays, let us try to figure out why arrays are more popular in
imperative languages, while lists are the more natural choice to use in
functional languages.
Imperative Languages
An arrays is as simple as it gets as far as data structures are concerned. It's just a big chuck of memory, divided into slots where we can store data items. The address of a slot in memory can be calculated in constant time by adding the slot index multiplied by the slot size to the starting address of the whole array. Thus, arrays have the added benefit of providing constant-time random access to any array element.
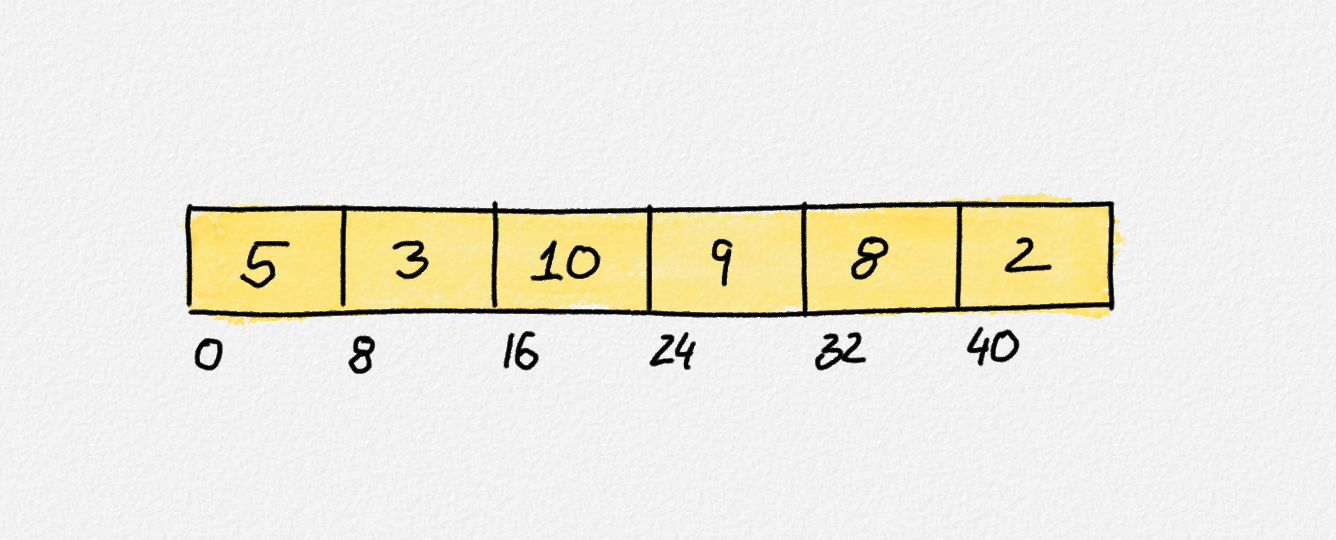
An array is just a big chunk of memory, which makes it space-efficient and allows them to support constant-time access to any array element. If we assume in this example that the array elements are 64-bit integers, then the array occupies \(6 \cdot 8 = 48\) bytes—there is no overhead for any book-keeping information—and the 3rd element is stored at the byte offset \(3 \cdot 8 = 24\) from the start of the array.
Lists, on the other hand, are more complex beasts. They require pointers to implement, use more space per element, and exhibit less locality in memory, which makes cache memory less effective to speed up access to list elements than for arrays. In more detail, a list is a collection of list nodes. Each such node stores a single list element and is generally stored on the heap as a separate object—hence the lack in locality. To indicate the order in which the list elements occur in the list, each list node stores a pointer to the next list node. The whole list is represented by storing a pointer to the first list node.
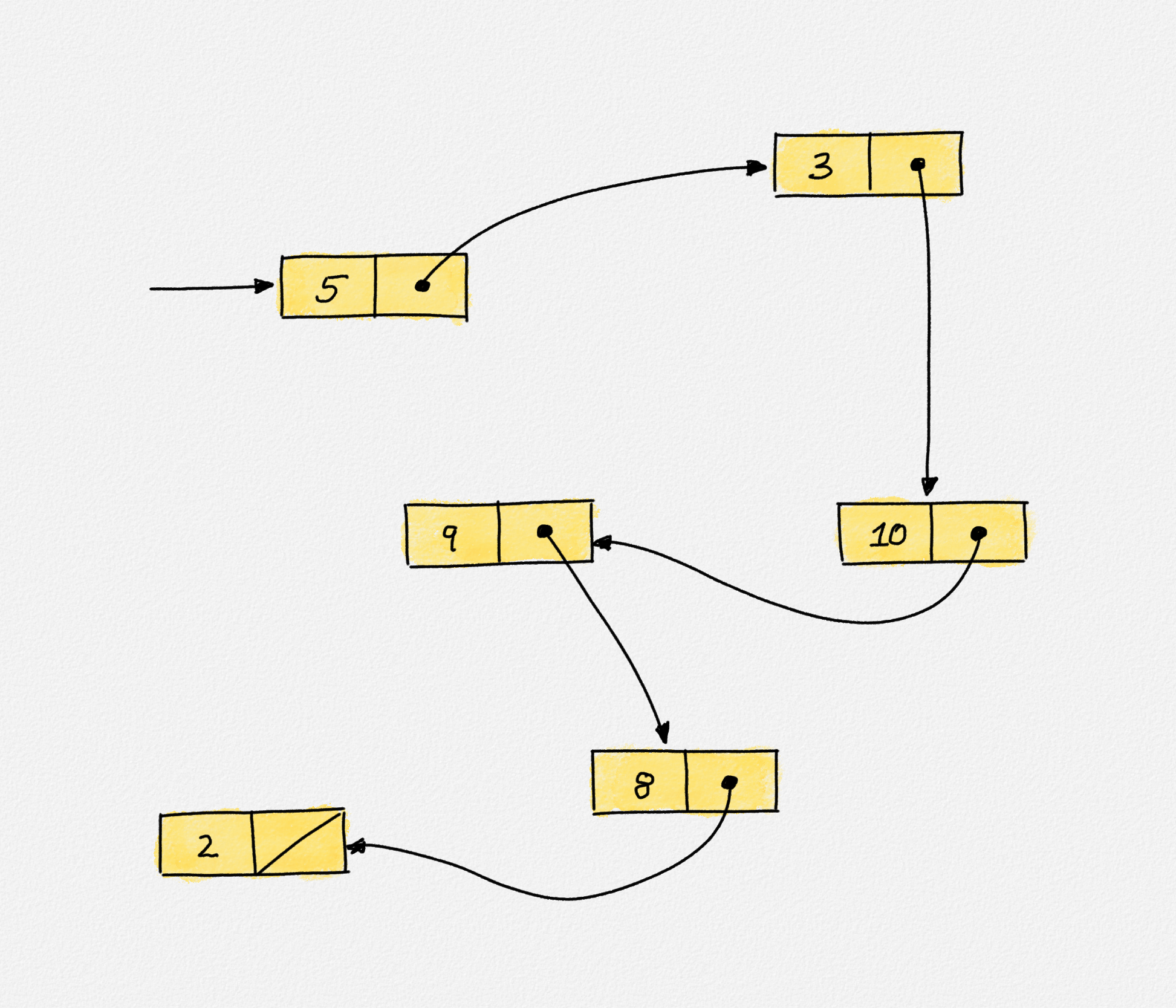
A singly-linked list storing the same elements as the array in the previous figure, in the same order. The list nodes are intentionally not shown in sequence, to highlight that list nodes can be stored anywhere on the heap, not necessarily consecutively nor in order. Each list element needs to be accompanied by a pointer to the next list node, creating an 8-byte space overhead per list element. Accessing any element requires accessing all the elements before it because following pointers from the start of the list is the only way to reach any list element; there is no way to calculate the address of a list element, as can be done for arrays.
In a singly-linked list, that's all there is. In a doubly-linked list, each node also stores a pointer to its predecessor in the list. This helps with speeding up some list operations. Here, we focus only on singly-linked lists, as they are how lists are represented in Haskell.
Since each list node stores a list element and a pointer to the next node, the space per list element is higher than in an array, which requires no pointer information. Furthermore, since list nodes are scattered all over heap memory, there is no efficient way to access the 10,000th node in the list. In an array, we can calculate the address of the 10,000th array element in constant time. In a list, the only way we can get to the 10,000th element is by walking down the list, visiting all the 9,999 list nodes before it.
And that's the reason why imperative programmers prefer arrays: They're simpler. They're faster. They're smaller. Only for some algorithmic problems, lists give us better performance than arrays, and then what we really need is often doubly-linked lists.
Functional Languages
Since our CPU with its memory is a primitive imperative machine, the implementation of lists in functional languages does not magically become simpler than in imperative languages. Under the hood, they are still a soup of list nodes with pointers among them, with all the drawbacks: size, less cache-efficiency, no random access, more complex pointer-based implementation. So why are they the goto representation of sequences in functional languages?
First, the complexity of maintaining the list structure is hidden from the functional programmer by building lists right into the language's runtime system. Or rather, we can define lists simply as
data List a = Empty | Cons a (List a)
A value constructed as Cons x xs is actually stored on the heap, and its two
fields store pointers to the values they store. This is because most
functional languages use a reference model of variables, which gives us pointers
for free.
All the pointer mess is hidden from us, but the efficiency concerns don't go away. So arrays still seem like the better choice. Here's the reason why they aren't. Remember, there are no destructive updates in functional languages. If we want to "update" an array, we actually need to make a copy of the entire array, with the updated array slots storing new values. If we update a whole lot of array slots in one shot, then this may be efficient, but updating a single array slot is terribly inefficient. It takes linear time because we need to copy the whole array.
Lists allow us much more fine-grained changes. First of all, they can be defined
recursively, as we did for our List a type above:
- A list is empty or
- It consists of an element followed by a list containing the remaining elements.
This recursive definition fits perfectly with using only recursion to do repetitive things in functional languages. To define pretty much any function on lists, we figure out what to do with the empty list. For the non-empty list, we figure out what to do with its first element and then recursively deal with the remainder of the list.
Moreover, the fact that values cannot be updated—we can only create new values
from old ones—is a blessing when working with lists. If we want to create a list
ys that stores some element x as the first element and whose remaining
elements are the same as in some list xs, we can construct this list as
ys = Cons x xs. This takes constant time no matter how long xs is, because
all we do is create a list node that stores pointers to x and to xs. As a
result, xs and ys share a whole lot of list nodes:
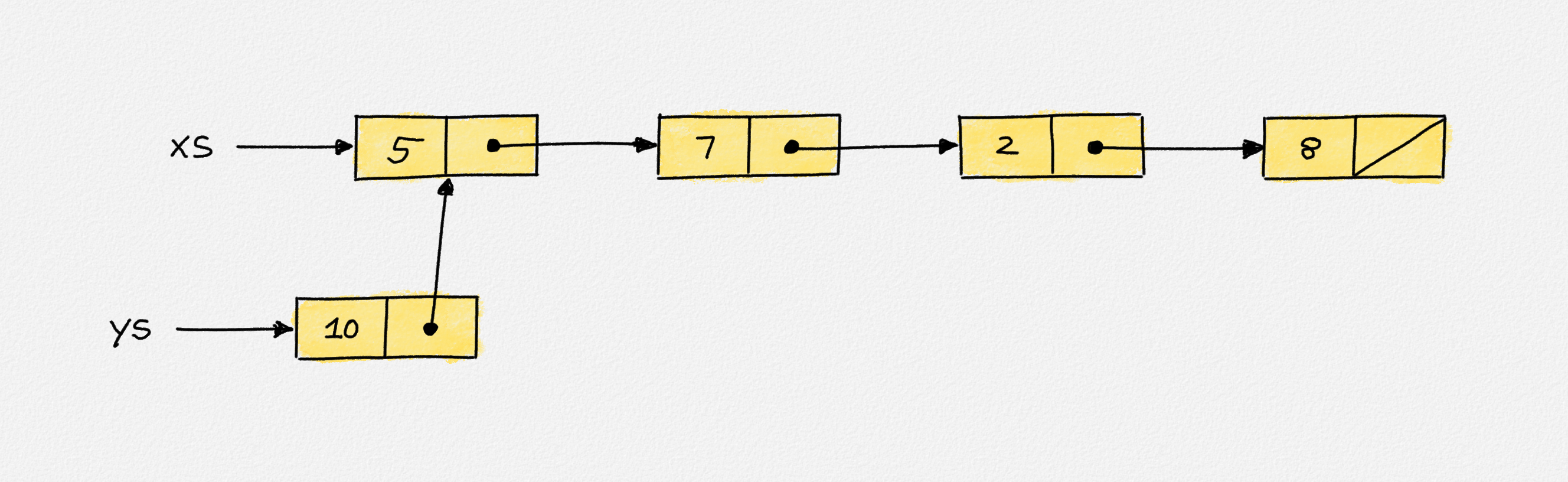
If xs = Cons 5 (Cons 7 (Cons 2 (Cons 8 Nil)))
and ys = Cons 10 xs, then xs and ys share all of xs list nodes. ys's
head node points to the head node of xs as its successor.
In an imperative language with destructive updates, this would be a problem: Any
update to a list node in xs would also be visible in ys, and vice versa.
Given that we cannot update list nodes in functional languages, this cannot
happen in functional languages. It is perfectly safe for lists to share nodes.
The result is that any list operation, even ones that "update" list nodes, take time proportional to the number of list nodes they visit, which can be less than the size of the list. For arrays, every array update has a cost proportional to the size of the array.
This raises another question: Why then do we also have arrays in Haskell? Because of this little caveat that arrays provide constant-time access to array elements, and lists do not. For some algorithms, this constant-time access is crucial, even if the array we access is read-only. Moreover, combined with bulk updates and Haskell's lazy evaluation, there are lots of algorithms that we can implement efficiently on top of immutable arrays even though they seem to require fine-grained element-by-element updates, which would be inefficient in Haskell. We will look at this in detail in the next sections.