|
||||||||||

|
|
 Mission
Statement Mission
Statement
Once a software product is released, it enters into the maintenance phase and goes through many major or minor
changes. These changes (a.k.a., maintenance activities) can be triggered by several factors including post-release
bugs, requests for new features, or even by the need to adapt to new technologies (e.g., Generative AI).
Unfortunately, these activities have never been easy despite 40+ years of extensive research! Software
maintenance
activities claim up to ~50% of the developers' time and cost the global economy billions of dollars every
year. For
example, in 2017 alone, the global economy lost $1.7+ trillion due to software bugs, crashes, and failures.
With the
rise of popular but highly complex computing frameworks such as Large Language Models (LLM), Agentic AI, Deep
Learning, Cloud Computing, and Mobile Computing, software maintenance has become even more challenging and costlier.
 Signature
Research Areas Signature
Research Areas
 Automation of Software
Debugging Automation of Software
Debugging
Software bugs, crashes, and failures are inevitable!
In 2017 alone, 606 software bugs cost the global economy $1.7 trillion+, with 3.7 billion people
affected and 314 companies impacted! While these bugs are hard to tackle, new classes of software bugs have
emerged due to the adoption of popular but highly
complex technologies such as Large Language Models (LLM), Agentic AI, Deep learning, Cloud computing, and Mobile
Computing.
Many of these bugs are hidden not only in the software code but also in other artifacts including configuration
files, training data, model parameters, and deployment modules.
They are also non-deterministic, multi-faceted, and data-driven unlike the traditional software
bugs, which are
commonly logic-driven. Thus, the traditional methods of debugging, developed over the last 40+ years,
might not be enough
to tackle these emerging, complex bugs.
 AI for Code Review AI for Code Review
Once software code is modified, it must be checked for errors or quality issues. Over the last 35+ years,
software developers
have been using code review, an engineering practice, to ensure the quality of the software code.
However, it is often a time-consuming and error-prone process, which can be further exacerbated by the
increasing complexity of modern software systems and the selection of inappropriate reviewers.
Poorly written reviews often contain inaccurate suggestions and suffer
from a lack of clarity or empathy when pointing out mistakes in the software code, which makes the reviews
ineffective.
Even at Microsoft Corporation, where 50,000+ professional developers spend
six hours every week reviewing each other’s code, ~35% of their code reviews are ineffective in improving
software quality.
 AI for Code Search AI for Code Search
While resolving bugs in the software is crucial, the majority of the maintenance budget (e.g.,
~50%) is spent incorporating new features in the existing software (a.k.a., feature enhancement).
However, modifying an existing software containing thousands of lins of code is not always straightforward.
A developer must know (a) how to implement a new feature and (b) where to add this feature within the software
code. Thus, developers often search for the right location within the the codebase by manually formulating
and executing queries from a feature request.
However, according to existing surveys, they might fail to find the right location ~88% of the time,
which is a significant
waste of their valuable development time.
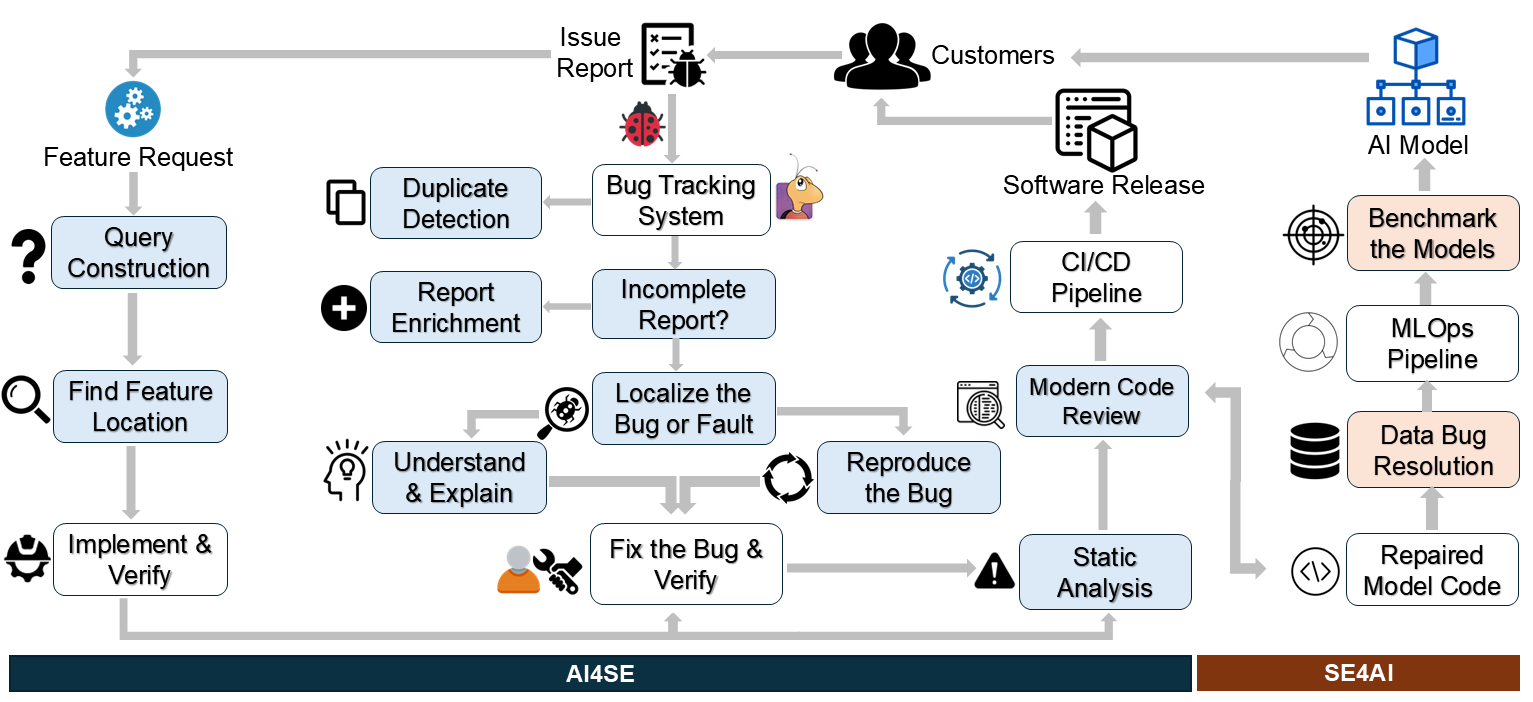
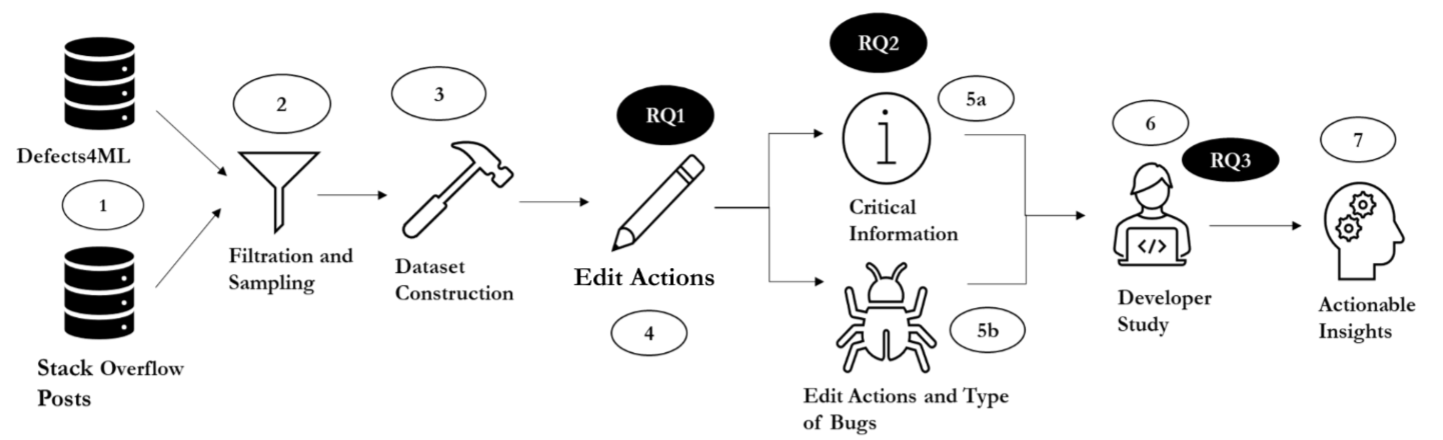
In RAISE Lab, we have been advancing the highlighted steps (e.g., light blue, light orange) of the software maintenance and evolution pipelines below.
 Research Topics, Methods & Technologies
Research Topics, Methods & Technologies
 RAISE Team
RAISE Team
 RAISE Graduates
RAISE Graduates
RAISE Interns & Visitors
 Join RAISE!
Join RAISE!
No funded position right now! However, please book an appointment if you want to discuss your research interests.  Recent Projects
Recent Projects
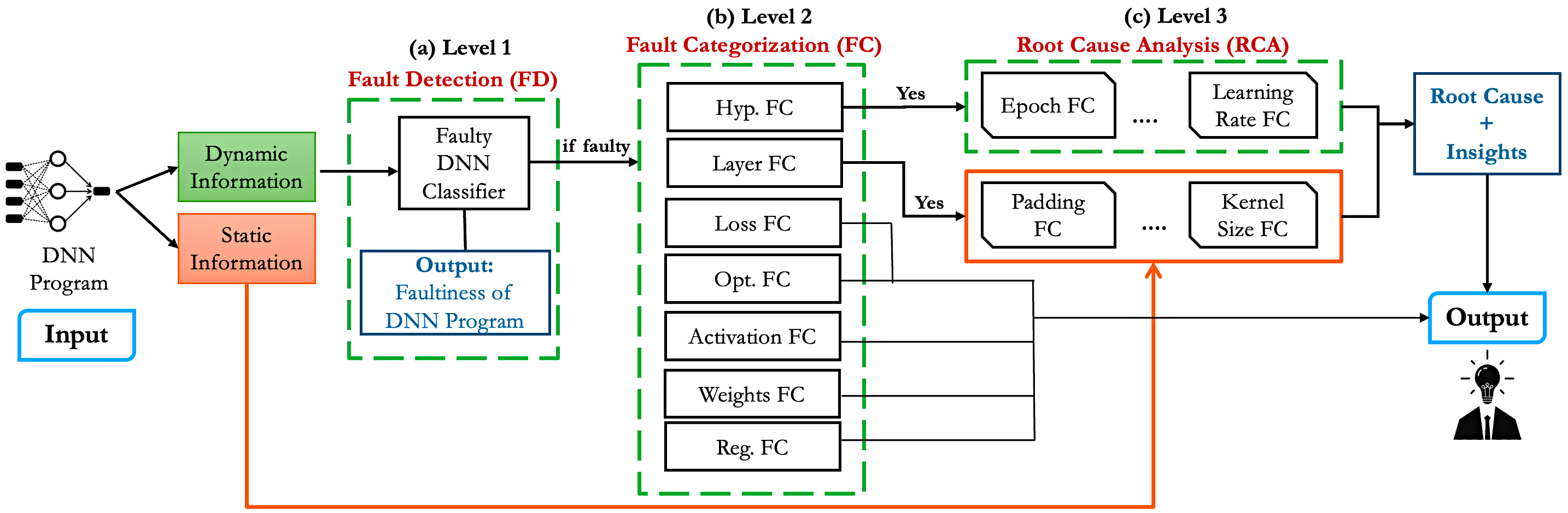
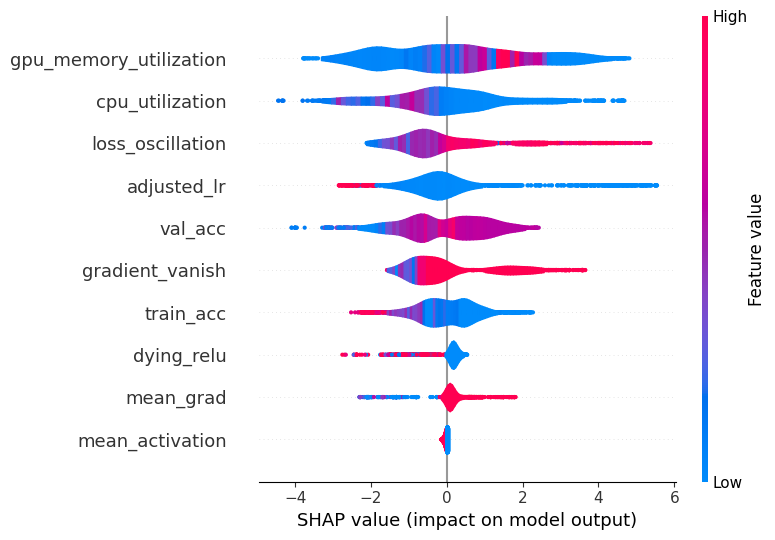
Improved Detection and Diagnosis of Faults in Deep Neural Networks Using
Hierarchical and Explainable Classification [ICSE 2025]
Overview: Deep Neural Networks (DNNs) have been widely used in various applications, such as autonomous vehicles, medical diagnosis, software development, and natural language processing. However, DNNs are prone to faults, which can lead to severe consequences. In this work, we present DEFault (Detect and Explain Fault) -- a novel technique to detect and diagnose faults in DNN programs. It first captures dynamic (i.e., runtime) features during model training and leverages a hierarchical classification approach to detect all major fault categories from the literature. Then, it captures static features (e.g., layer types) from DNN programs and leverages explainable AI methods (e.g., SHAP) to narrow down the root cause of the fault. We train and evaluate DEFault on a large, diverse dataset of ~14.5K DNN programs and further validate our technique using a benchmark dataset of 52 real-life faulty DNN programs. Our approach achieves ~94% recall in detecting real-world faulty DNN programs and ~63% recall in diagnosing the root causes of the faults, demonstrating 3.92%--11.54% higher performance than that of state-of-the-art techniques. Explore more ...
deep-learning bug-localization tools-techniques 
Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical
Study [EMSE 2024]
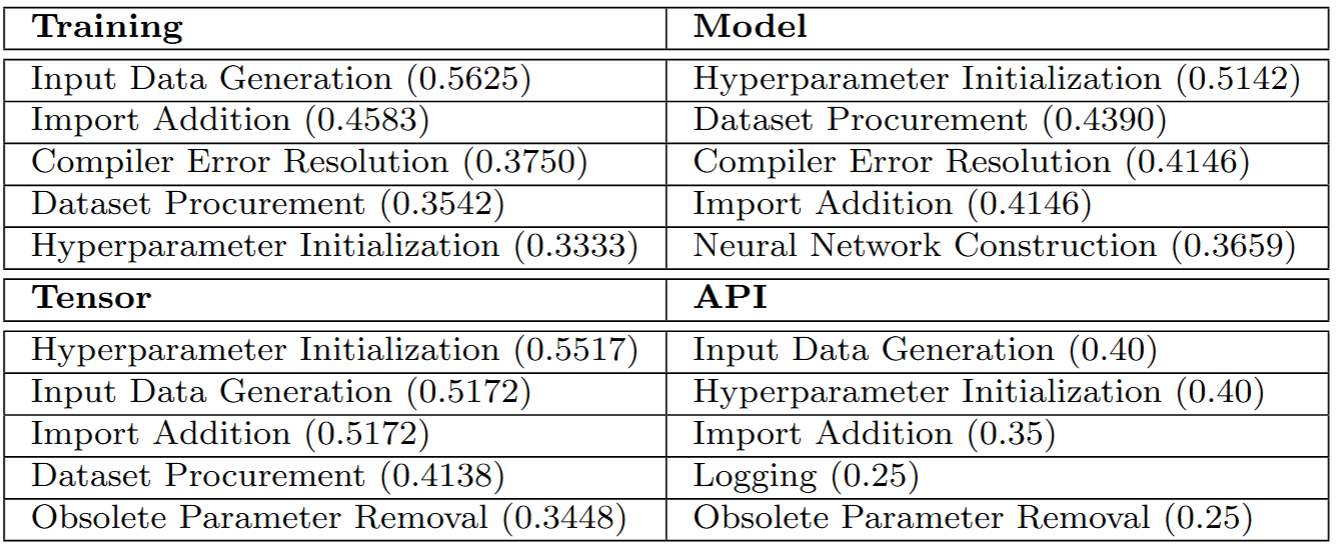
Overview: Deep learning has seen significant progress across various fields. However, like any software system, deep learning models have bugs, some with serious consequences, such as crashes in autonomous vehicles. Reproducing deep learning bugs, a prerequisite for their resolution, has been a major challeng According to an existing work, only 3% of deep learning bugs are reproducible. In this work, we investigate deep learning bug reproducibility by creating a dataset of 668 bugs from platforms like Stack Overflow and GitHub and by reproducing 165 bugs. While reproducing these bugs, we identify edit actions and useful information for their reproduction. Then we used the Apriori algorithm to identify useful information and edit actions required to reproduce specific types of bugs. In a study involving 22 developers, our recommended information from the Apriori algorithm increased bug reproducibility by 22.92% and reduced reproduction time by 24.35%. These findings provide valuable insights to help practitioners and researchers enhance reproducibility in deep learning systems. Explore more ...
deep-learning empirical-study bug-reproduction
Improved IR-based Bug Localization with Intelligent Relevance Feedback [ICPC
2025]
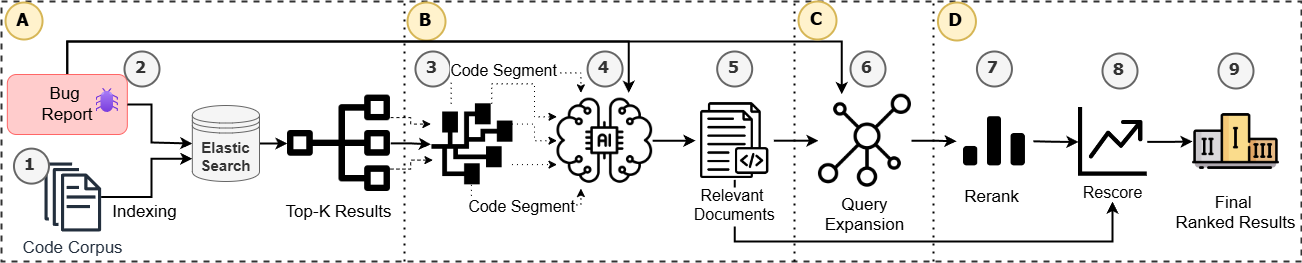
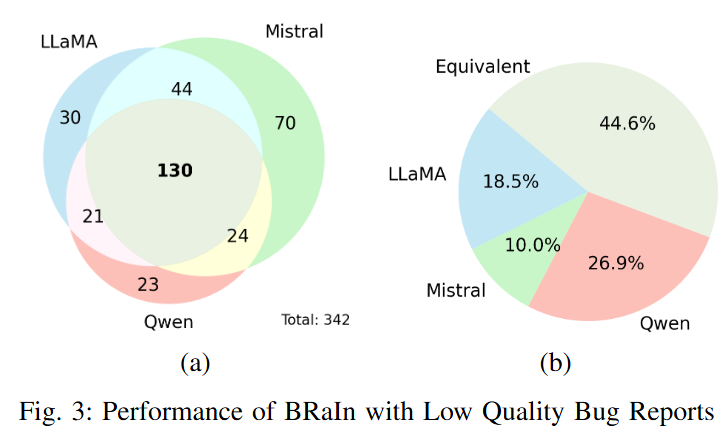
Overview: In this project, we present a novel technique - BRaIn - for bug localization that addresses the contextual gaps between bug reports and source code using Large Language Models (LLM). We leverage LLM’s feedback (a.k.a., Intelligent Relevance Feedback) to reformulate queries and re-rank source documents, improving bug localization. We evaluate BRaIn using a benchmark dataset --Bench4BL-- and three performance metrics and compare it against six baseline techniques from the literature. Our experimental results show that BRaIn outperforms baselines by 87.6%, 89.5%, and 48.8% margins in MAP, MRR, and HIT@K, respectively. Additionally, it can localize ~52% of bugs that cannot be localized by the baseline techniques due to the poor quality of corresponding bug reports. Explore more ...
query-reformulation bug-localization Large-Language-Model information-retrieval tools-techniques
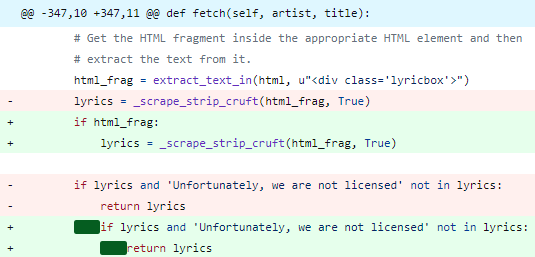
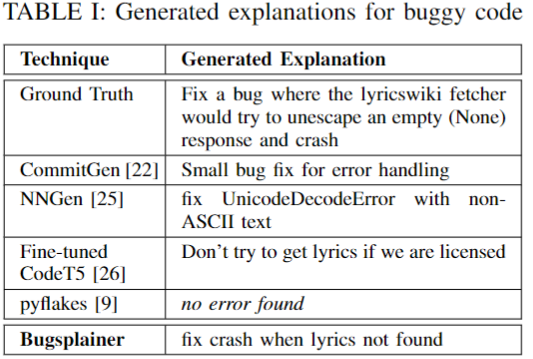
Explaining Software Bugs Leveraging Code Structures in Neural Machine
Translation [ICSE 2023 + ICSME 2023]
Overview: Software bugs claim ≈ 50% of development time and cost the global economy billions of dollars. Over the last five decades, there has been significant research on automatically finding or correcting software bugs. However, there has been little research on automatically explaining the bugs to the developers, which is a crucial but highly challenging task. To fill this gap, we developed Bugsplainer, a transformer-based generative model, that generates natural language explanations for software bugs by learning from a large corpus of bug-fix commits. Bugsplainer can leverage structural information and buggy patterns from the source code to generate an explanation for a bug. A developer study involving 20 participants shows that the explanations from Bugsplainer are more accurate, more precise, more concise and more useful than the baselines. Explore more ...
bug-explanation deep-learning neural-text-generation transformer-based-model 
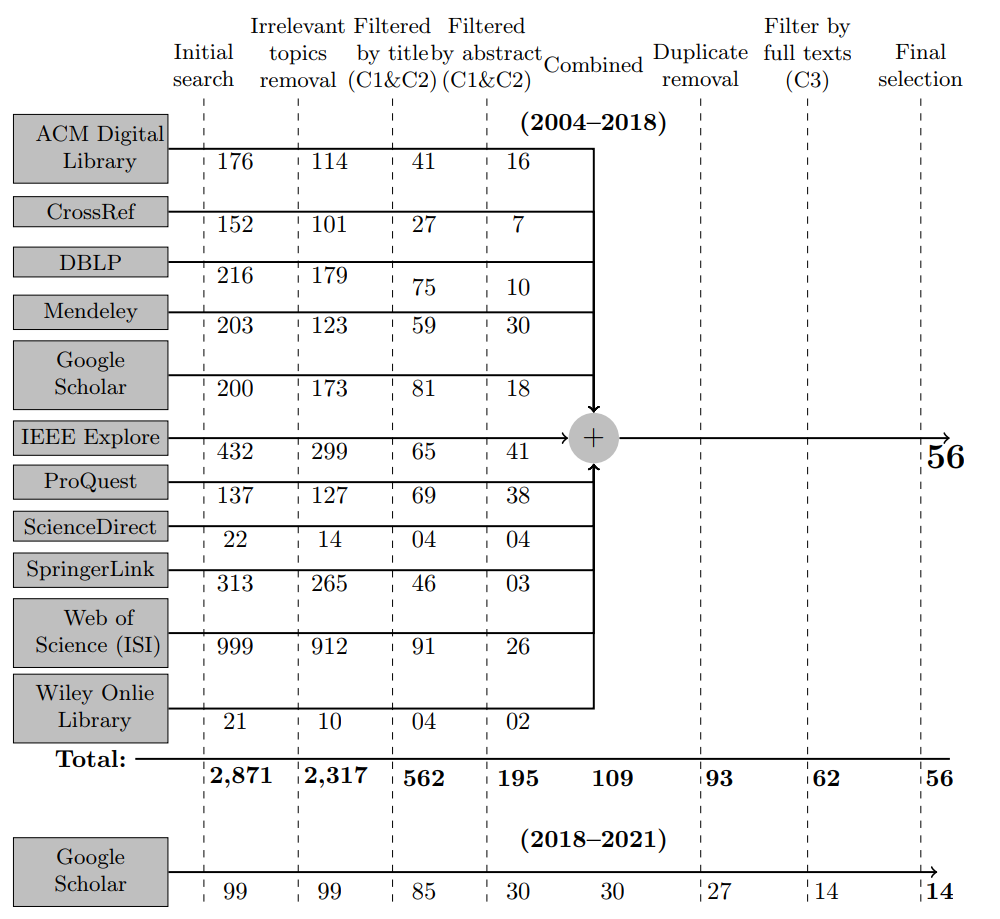
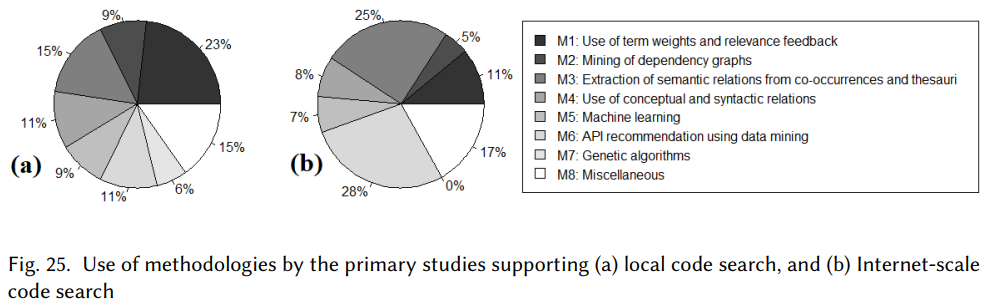
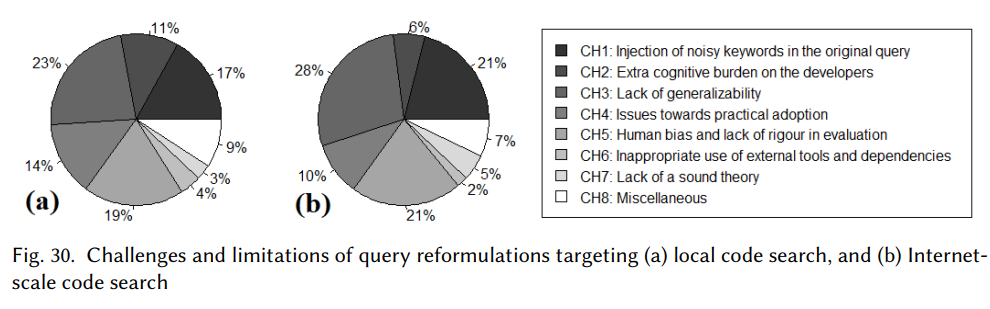
A Systematic Review of Automated Query Reformulations in Source Code Search
[TOSEM 2023]
Overview: In this systematic literature review, we carefully select 70 primary studies on query reformulations from 2,970 candidate studies, perform an in-depth qualitative analysis using the Grounded Theory approach, and then answer seven important research questions. Our investigation has reported several major findings. First, to date, eight major methodologies (e.g., term weighting, query-term co-occurrence analysis, thesaurus lookup) have been adopted in query reformulation. Second, the existing studies suffer from several major limitations (e.g., lack of generalizability, vocabulary mismatch problem, weak evaluation, the extra burden on the developers) that might prevent their wide adoption. Finally, we discuss several open issues in search query reformulations and suggest multiple future research opportunities. Explore more ...
query-reformulation bug-localization concept-location code-search empirical-study grounded-theory
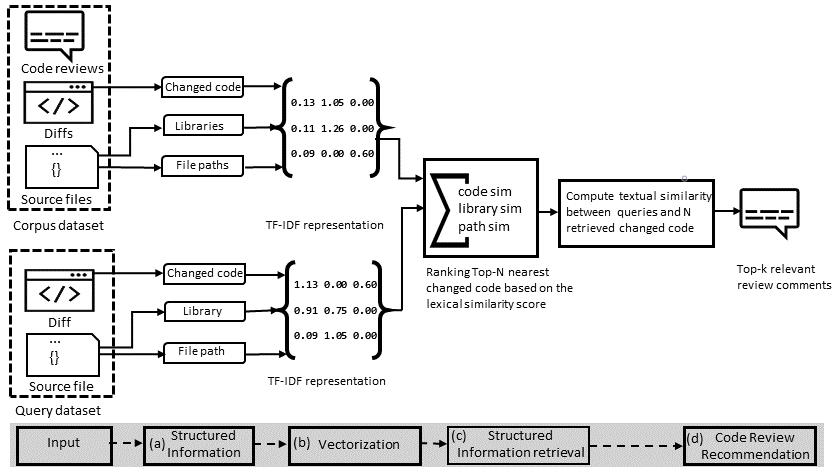
Recommending Code Reviews Leveraging Code Changes with Structured Information
Retrieval [ICSME 2023]
Overview: Review comments are one of the main building blocks of modern code reviews. Manually writing code review comments could be time-consuming and technically challenging. In this work, we propose a novel technique for relevant review comments recommendation -- RevCom -- that leverages various code-level changes using structured information retrieval. It uses different structured items from source code and can recommend relevant reviews for all types of changes (e.g., method-level and non-method-level). We find that RevCom can recommend review comments with an average BLEU score of ≈ 26.63%. According to Google's AutoML Translation documentation, such a BLEU score indicates that the review comments can capture the original intent of the reviewers. Our approach is lightweight compared to DL-based techniques and can recommend reviews for both method-level and non-method-level changes where the existing IR-based technique falls short. Explore more ...
structured-information-retrieval code-review-automation
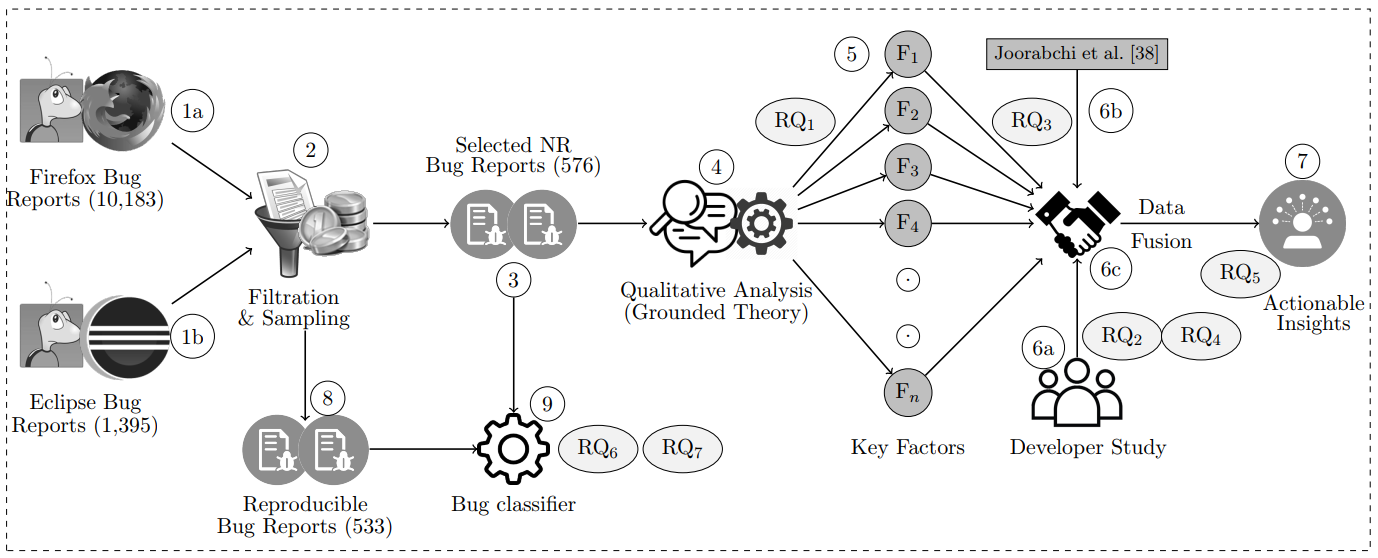
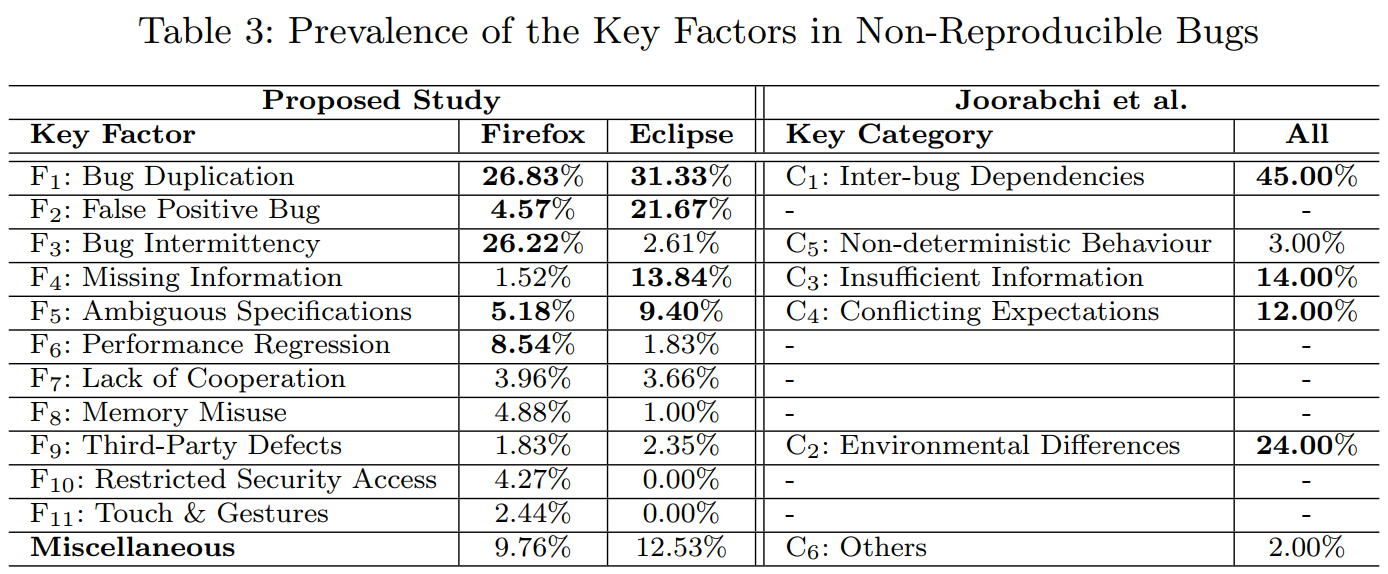
Why Are Some Bugs Non-Reproducible? An Empirical Investigation using Data
Fusion [ICSME 2020 + EMSE 2022]
Overview: We conduct a multimodal study to better understand the non-reproducibility of software bugs. First, we perform an empirical study using 576 non-reproducible bug reports from two popular software systems (Firefox, Eclipse) and identify 11 key factors that might lead a reported bug to non-reproducibility. Second, we conduct a user study involving 13 professional developers where we investigate how the developers cope with non-reproducible bugs. We found that they either close these bugs or solicit for further information, which involves long deliberations and counter-productive manual searches. Third, we offer several actionable insights on how to avoid non-reproducibility (e.g., false-positive bug report detector) and improve reproducibility of the reported bugs (e.g., sandbox for bug reproduction) by combining our analyses from multiple studies (e.g., empirical study, developer study). Explore more ...
empirical-study data-fusion bug-reproduction grounded-theory
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




















 All Projects & Publications
All Projects & Publications Automated Software Debugging
Automated Software Debugging|
Overview: Bug Doctor assists the developers in
localizing the software code of interest (e.g., bugs,
concepts and reusable code) during software maintenance.
In particular, it reformulates a given search query (1) by
designing a novel keyword selection algorithm (e.g.,
CodeRank)
that outperforms the traditional alternatives (e.g.,
TF-IDF),
(2) by leveraging the bug report quality paradigm and source
document structures which were previously overlooked and
(3) by exploiting the crowd knowledge and word semantics
derived from Stack Overflow Q&A site, which were previously
untapped.
An experiment using 5000+ search queries (bug reports,
change requests, and ad hoc queries) suggests
that Bug Doctor can improve the given queries significantly
through automated query reformulations.
Comparison with 10+ existing studies on bug localization,
concept location and Internet-scale code
search suggests that Bug Doctor can outperform the
state-of-the-art approaches with a significant margin.
Explore
more ...
query-reformulation bug-localization concept-location code-search
|
Overview: BLIZZARD is a novel technique for IR-based bug localization that uses query reformulation and bug report quality dynamics. We first conduct an empirical study to analyse the report quality dynamics of bug reports and then design an IR-based bug localization technique using graph-based keyword selection, query reformulation, noise filtration, and Information Retrieval. Explore more ...
query-reformulation bug-localization
Overview: CodeInsight is an automated technique for generating insightful comments for source code using crowdsourced knowledge from Stack Overflow. It uses data mining, topic modelling, sentiment analysis and heuristics for deriving the code-level insights. Explore more ...
data-mining stack-overflow
 Automated Code Review
Automated Code Review
Overview: Review comments are one of the main building blocks of modern code reviews. Manually writing code review comments could be time-consuming and technically challenging. In this work, we propose a novel technique for relevant review comments recommendation -- RevCom -- that leverages various code-level changes using structured information retrieval. It uses different structured items from source code and can recommend relevant reviews for all types of changes (e.g., method-level and non-method-level). We find that RevCom can recommend review comments with an average BLEU score of ≈ 26.63%. According to Google's AutoML Translation documentation, such a BLEU score indicates that the review comments can capture the original intent of the reviewers. Our approach is lightweight compared to DL-based techniques and can recommend reviews for both method-level and non-method-level changes where the existing IR-based technique falls short. Explore more ...
structured-information-retrieval code-review-automation
|
CORRECT: Code Reviewer Recommendation in GitHub
Based on Cross-Project and Technology Experience [ICSE
2016 + ASE 2016]
|
||
|
Overview: We propose a heuristic ranking technique
that considers not only the cross-project work history of a
developer but
also her experience in certain technologies associated with
a pull request for determining her expertise as a potential
code reviewer.
We first motivate our technique using an exploratory study
with 20 commercial projects. We then evaluate the technique
using 13,081 pull
requests from ten projects, and report 92.15% accuracy,
85.93% precision and 81.39% recall in code reviewer
recommendation which outperforms the state-of-the-art
technique.
This project was funded by NSERC Industry Engage grant and
was done in collaboration with Vendasta Technologies. Explore
more ...
code-review-automation data-mining
|
||
Overview: RevHelper predicts the usefulness of code review comments based on their texts and developers' experience. We first conduct an empirical study where we contrast between hundreds of useful and non-useful review comments from multiple commercial projects. Then we collect features from comment texts and reviewers' experience, and apply Random Forest algorithm to them for the usefulness prediction. Explore more ...
code-review-automation data-mining
 Automated Code Search
Automated Code Search
Overview: STRICT is a novel technique for identifying appropriate search terms from a software change request. It leverages the co-occurrences and syntactic dependencies among terms as a proxy to their importance. STRICT uses graph-based term weighting (PageRank), natural language processing and Information Retrieval to identify the important keywords from a change request, and then finds the code of interest (e.g., software feature). Explore more ...
query-reformulation concept-location
Overview: ACER offers effective reformulations to search queries leveraging CodeRank, an adaptation of PageRank to source code documents. It uses graph-based term weighting, query difficulty analysis, machine learning, and Information Retrieval to reformulate queries and find the code of interest. Explore more ...
query-reformulation concept-location
|
RACK: Automatic Query Reformulation for Code Search using
Crowdsourced Knowledge [SANER 2016 + EMSE 2019 + ICSE
2017]
|
||
|
Overview: We propose a novel query reformulation
technique--RACK--that suggests a list of relevant API
classes for a natural language query intended for code
search. Our technique offers such suggestions by exploiting
keyword-API associations from the questions and answers of
Stack Overflow (i.e., crowdsourced knowledge).
We first motivate our idea using an exploratory study with
19 standard Java API packages and 344K Java related posts
from Stack Overflow. Experiments using 175 code search
queries randomly chosen from three Java tutorial sites show
that our technique recommends correct API classes within the
Top-10 results for 83% of the queries, with 46% mean average
precision and 54% recall, which are 66%, 79% and 87% higher
respectively than that of the state-of-the-art.
Reformulations using our suggested API classes improve 64%
of the natural language queries and their overall accuracy
improves by 19%. Comparisons with three state-of-the-art
techniques demonstrate that RACK outperforms them in the
query reformulation by a statistically significant margin.
Investigation using three web/code search engines shows that
our technique can significantly improve their results in the
context of code search.
Explore
more ...
query-reformulation code-search stack-overflow
|
||
Overview: NLP2API expands a natural language query, intended for Internet-scale code search, leveraging crowdsourced knowledge and extra-large data analytics (e.g., semantic similarity) derived from Stack Overflow Q & A site. It also leverages Borda count to rank the most appropriate API classes for a given query. Explore more ...
query-reformulation code-search stack-overflow
Overview: In this work, we propose CROKAGE (Crowd Knowledge Answer Generator), a tool that takes the description of a programming task (the query) as input and delivers a comprehensible solution for the task. Our solutions contain not only relevant code examples but also their succinct explanations written by human developers. Explore more ...
query-reformulation search-engine stack-overflow
|
SurfClipse: Context-Aware IDE-Based Meta Search
Engine for Programming Errors & Exceptions [CSMR-WCRE
2014 + ICSME 2014 + WCRE 2013]
|
||
|
Overview:
We propose a context-aware meta search tool, SurfClipse,
that analyzes an encountered exception andits context in the
IDE, and recommends not only suitable search queries but
also relevant web pages for the exception (and its context).
The tool collects results from three popular search engines
and a programming Q & A site against the exception in the
IDE, refines the results for relevance against the context
of the exception, and then ranks them before recommendation.
It provides two working modes--interactive and proactive to
meet the versatile needs of the developers, and one can
browse the result pages using a
customized embedded browser provided by the tool. Explore
more ...
recommendation-system search-engine stack-overflow
|
||
|
ExcClipse: Context-Aware Meta Search Engine for Programming Errors and
Exceptions
|
||
|
Overview: In this MSc thesis, we develop a context-aware, IDE-based, meta search
engine --ExcClipse-- that delivers relevant web pages and code examples within the IDE
panel
for dealing with programming errors and exceptions. Once a programming error/exception
is encountered, the tool (1) constructs an appropriate query by capturing
the error details and meta data, (2) collects results from popular search
engines--Google, Bing, Yahoo, StackOverflow and GitHub,
(3) refines and ranks the results against the context of the encountered exception, and
(4) then recommends them within the IDE.
We develop our solution as an Eclipse plug-in prototype. Explore more ...
recommendation-system search-engine stack-overflow
|
||
 Software
Quality Control
Software
Quality Control
Overview: In this work, we detect code smells in simulation modelling systems and contrast their prevalence, evolution, and impact with those of traditional software systems. We found that code smells are more prevalent and long-lived in simulation systems. Explore more ...
simulation-system code-smells
Overview: In this work, we perform a comparative analysis between deep learning and traditional open-source applications collected from GitHub. We have several major findings. First, long lambda expression, long ternary conditional expression, and complex container comprehension smells are frequently found in deep learning projects. That is, deep learning code involves more complex or longer expressions than the traditional code does. Second, the number of code smells increases across the releases of deep learning applications. Third, we found that there is a co-existence between code smells and software bugs in the studied deep learning code, which confirms our conjecture on the degraded code quality of deep learning applications. Explore more ...
deep-learning code-smells
Overview: In this work, we conduct an empirical study to investigate the prevalence and evolution of SQL code smells in open-source, data-intensive systems. We collected 150 projects and examined both traditional and SQL code smells in these projects. Overall, our results show that SQL code smells are indeed prevalent and persistent in the studied data-intensive software systems. Developers should be aware of these smells and consider detecting and refactoring SQL code smells and traditional code smells separately, using dedicated tools. Explore more ...
deep-learning code-smells
 Automated Q&A
Automated Q&A
Overview: In this work, we conducted an exploratory study on the reproducibility of issues discussed in 400 Java and 400 Python questions. We parsed, compiled, executed, and carefully examined the code segments from these questions to reproduce the reported programming issues. The study found that approximately 68% of Java and 71% of Python issues were reproducible, with many requiring modifications, while 22% of Java and 19% of Python issues were irreproducible. It also revealed that reproducible questions are twice as likely to receive accepted answers more quickly, with confounding factors like reputation not affecting this correlation. Explore more ...
stack-overflow question-answering
Overview: In this study, we conduct an empirical study investigating the cause & effect of missing code snippets in SO questions whenever required. The study shows that questions including required code snippets during submission are three times more likely to receive accepted answers, and confounding factors like user reputation do not affect this correlation. A survey of practitioners revealed that 60% of users are unaware of when code snippets are needed in their questions. To address this, the researchers developed machine learning models with high accuracy (85.2%) to predict questions needing code snippets, potentially improving programming Q&A efficiency and the quality of the knowledge base. Explore more ...
stack-overflow question-answering
Overview: In this article, we compare the subjective assessment of questions with their objective assessment using 2.5 million questions and ten text analysis metrics. According to our investigation, (1) four objective metrics agree, (2) two metrics do not agree, (3) one metric either agrees or disagrees, and (4) the remaining three metrics neither agree nor disagree with the subjective evaluation. We then develop machine learning models to classify the promoted and discouraged questions. Our models outperform the state-of-the-art models with a maximum of about 76%--87% accuracy. Explore more ...
stack-overflow question-answering
Overview: In this paper, we investigate 3,956 such unresolved questions using an exploratory study where we analyze four important aspects of those questions, their answers and the corresponding users that partially explain the observed scenario. We then propose a prediction model by employing five metrics related to user behaviour, topics and popularity of question, which predicts if the best answer for a question at Stack Overflow might remain unaccepted or not. Experiments using 8,057 questions show that the model can predict unresolved questions with 78.70% precision and 76.10% recall. Explore more ...
stack-overflow question-answering
 Theses, Dissertations & RAD
Theses, Dissertations & RAD
Overview: This thesis investigates the code quality of simulation software systems, an area that has received limited attention in software engineering research despite their wide use in science, planning, and industry. Through two large-scale empirical studies on GitHub projects, the work reveals that implementation-level code smells (e.g., Magic Numbers, Long Statements) are more prevalent and persistent in simulation systems than in traditional software, though they do not correlate with bugs. The second study shows that while refactoring removes about 35% of code smells and reduces complexity, method-level refactorings often introduce more smells than they eliminate, making them risky. Overall, the findings highlight unique code quality challenges in simulation software and provide developers with insights to improve maintainability and reliability.
simulation-system code-smells mcs-thesis
Overview: Despite years of research, finding software bugs remains difficult, with developers spending nearly half their time on bug-related tasks. Traditional Information Retrieval (IR)-based techniques often fall short due to their inability to fully understand the complex relationships between bug reports and source code. To address these limitations, this RAD report conducts two studies that enhance IR-based bug localization by using Large Language Models (LLMs) for better reasoning. The first study fine-tunes a model like CodeBERT and shows significant improvements in metrics such as MAP, MRR, and HIT@K. The second study introduces Intelligent Relevance Feedback (IRF) from LLMs like Mistral to refine queries, resulting in even greater improvements and the ability to localize bugs that previous methods could not.
bug-localization deep-learning research-aptitude-defence
Overview:In this RAD report, the author conducts two complementary studies. There exists a critical gap in understanding the symptoms of data bugs in deep learning. The first study analyzes code-based, text-based, and metric-based datasets to explore how data bugs affect model behavior, training dynamics, and internal representations. In a follow-up study, the authors collected 668 bugs, manually reproduced 148 of them, and identified key edit actions and component information necessary for successful bug reproduction. They applied the Apriori algorithm to recommend helpful reproduction strategies. A user study showed that these recommendations significantly improved bug reproduction success rates by 22.92% and reduced reproduction time by 24.35%
bug-reproduction deep-learning research-aptitude-defence
Overview: Software bugs have a massive economic impact and consume about half of developers' time, with duplicate detection and localization being particularly difficult tasks. Although IR-based techniques are computationally efficient and have been used for bug report management over the past two decades, they remain underutilized, prompting further study. In this RAD report, the author conducts an empirical study on 92,854 bug reports, analyzing both textually similar and dissimilar duplicates, and finds that current techniques struggle with dissimilar duplicates due to missing critical information. They also evaluate IR-based methods for localizing bugs in 2,365 deep-learning and 2,913 traditional system bugs, revealing poor performance especially in deep-learning contexts. This underperformance is attributed to the unique nature of deep learning bugs, which often involve non-code artifacts like GPUs and training data.
bug-localization deep-learning research-aptitude-defence
Overview: This thesis introduces Bugsplorer, a deep-learning technique for line-level defect prediction, demonstrating 26-72% better accuracy than existing methods and efficient ranking of vulnerable lines. Additionally, Bugsplainer, a transformer-based generative model, provides natural language explanations for software bugs, outperforming multiple baselines according to evaluation metrics and a developer study with 20 participants. The empirical evidence suggests that these techniques have the potential to substantially reduce Software Quality Assurance costs. Explore more ...
bug-explanation deep-learning neural-text-generation transformer-based-model mcs-thesis
Overview: This thesis first conducts an empirical study, revealing significant performance variations in existing techniques for assessing code reviews between open-source and closed-source systems. The study indicates that less experienced developers tend to submit more non-useful review comments in both contexts, emphasizing the need for automated support in code review composition. To help developers write better review comments, another technique namely RevCom was proposed. RevCom utilizes structured information retrieval and outperforms both Information Retrieval (IR)-based and Deep Learning (DL)-based baselines, offering a lightweight and scalable solution with the potential to alleviate cognitive effort and save time for reviewers. Explore more ...
structured-information-retrieval code-review-automation mcs-thesis
Overview: This thesis introduces and assesses two novel Generative AI approaches for enhancing deficient bug reports. The first approach, BugMentor, utilizes structured information retrieval and neural text generation to provide contextually appropriate answers to follow-up questions in bug reports, demonstrating superior performance over three existing baselines in terms of metrics such as BLEU and Semantic Similarity. A developer study further validates BugMentor's effectiveness in generating more accurate, precise, concise, and useful answers. The second approach, BugEnricher, fine-tunes a T5 model on software-specific vocabulary to generate meaningful explanations, outperforming two baselines and showing promise in improving the detection of textually dissimilar duplicate bug reports, a known challenge in bug report management. The empirical evidence suggests these approaches hold strong potential for supporting bug resolution and enhancing bug report management. Explore more ...
bug-report-enhancement deep-learning neural-text-generation transformer-based-model mcs-thesis
Overview: The thesis extends an existing approach called STRICT to improve keyword selection for software change requests using graph-based algorithms like TextRank, POSRank, SimRank, Biased TextRank, and PositionRank. Experiments show that the enhanced approach, STRICT++, outperforms STRICT in detecting software bugs, with significant performance improvements in metrics like MAR, MRR, and Top-10 Accuracy. The thesis emphasizes the importance of capturing syntactic relationships and considers factors like word similarity, task-specific biases, and position information for effective keyword extraction. Explore more ...
bug-localization concept-location query-reformulation information-retrieval bcs-thesis

Overview: This thesis conducts a systematic review of automated program repair tools leveraging large language models, scrutinizing 1,276 papers published between 2017 and 2023 and narrowing down the analysis to 53 primary studies. The findings indicate a prevalent choice among these studies to utilize popular datasets and pre-trained models, specifically Defects4j and codeT5. The review reveals a tendency for studies to target specific aspects of program repair, such as validation or input representation, and underscores challenges in input representation, evaluation methods, and learning objectives, emphasizing the pivotal trade-off between efficacy and efficiency. Leveraging this comprehensive understanding, the thesis identifies future directions and best approaches for research on automated program repair using large language models. Explore more ...
bug-fixing deep-learning neural-code-generation transformer-based-model bcs-thesis
Overview: The thesis enhances the existing code search solution, RACK, by reimplementing it in Python and addressing the code search problem more effectively. The author constructs a token-API database through the analysis of Python posts on Stack Overflow, employing three co-occurrence-based heuristics—KKC, KAC, and KPAC—to establish relevance between natural language queries and API classes. The integrated RACK implementation becomes a VS-code plugin, enabling developers to input natural language queries and swiftly retrieve pertinent code examples from GitHub, thereby accelerating the problem-solving process in programming. Explore more ...
query-reformulation code-search stack-overflow bcs-thesis

Disclaimer: The overview of each thesis has been generated from their original abstracts using ChatGPT.
 Outreach, Milestones,
& Social
Outreach, Milestones,
& Social





















 and
and  for more updates on our research activities, publications, and events.
for more updates on our research activities, publications, and events.





Collaborators & Partners



