
Menu:
Research Projects
We are interested in research questions at the intersection of analytics, risk management, and high performance computing. Our research projects address challenges in catastrophe modeling, portfolio risk management, and dynamic financial analysis, by drawing on a diverse set of technologies including stochastic simulation, high performance computing, optimization, spatial OLAP, and data warehousing. Some of our projects are done hand-in-hand with industrial partners while others are more academically driven. Here is a list of some of our current projects.
Current Research Projects
Aggregate Risk Analysis
At the heart of the analytical pipeline of a modern quantitative insurance/reinsurance company sits Aggregate Risk Analysis, a stochastic simulation technique for portfolio risk analysis and risk pricing. Aggregate Analysis supports the computation of risk measures including Probable Maximum Loss (PML) and the Tail Value at Risk (TVAR) for a variety of complex property catastrophe insurance contract types including Per-Occurrence excess of loss (XL), Aggregate XL, and contracts that combine these such contractual features. 
In this project, we explore how high performance computing methods can be used to accelerate aggregate risk analysis. As part of this research we have developed a parallel aggregate risk analysis algorithm and implemented corresponding analysis engines on a variety of parallel computing platforms. These engines are implemented in C and OpenMP for multi-core CPUs and in C and CUDA for many-core GPUs. Performance analysis suggests that GPUs offer an alternative HPC solution for aggregate risk analysis that is quite cost effective. The optimized algorithm on GPUs performs a 1 million trial aggregate simulation with 1000 catastrophic events per trial on a typical exposure set and contract structure in just over 20 seconds which is approximately 15 times faster than the sequential counterpart. This is fast enough to support a real-time pricing scenario in which an underwriter analyses different contractual terms and pricing while discussing a deal with a client over the phone.
Parallel R-based Analytics on Cloud Infrastructure
Analytical workloads abound in application domains ranging from computational finance and risk analytics to engineering and manufacturing settings. In this project, we explore the use of Cloud Infrastructure to support large scale ad-hoc analytics, particularly those written using the statistical language R.

We are developing a Platform for Parallel R-based Analytics on the Cloud, called P2RAC. The goal of this platform is to allow an analyst to take a simulation or optimization job (both the code and associated data) that runs on their personal workstations and with minimum effort have them run on large-scale parallel cloud infrastructure. If this can be facilitated gracefully, an analyst with strong quantitative but perhaps more limited development skills can harness the computational power of the cloud to solve larger analytically problems in less time. P2RAC is currently designed for executing parallel R scripts on the Amazon Elastic Computing Cloud infrastructure.
Spatial OLAP
In recent years, there has been tremendous growth in the data warehousing market. Despite the sophistication and maturity of conventional database technologies, the ever-increasing size of corporate databases, coupled with the emergence of the new global Internet "database", suggests that new computing models are required to fully support many crucial data management and analysis tasks. In particular, the exploitation of parallel algorithms and architectures holds considerable promise, given their inherent capacity for both concurrent computation and data access.
We are interested in the design of parallel data mining and OLAP algorithms and their implementation on coarse grained clusters and clouds. To date we have been focusing on parallelization of data cube based methods. Data cube queries represent an important class of On-Line Analytical Processing (OLAP) queries in decision support systems. In addition to parallelization, we have focused on algorithms and data structures for spatial analysis. The resulting systems can then be used to dramatically accelerate visualization and query tasks associated with massive data sets. We are currently exploring applications in risk exposure analysis.
NextGen Dynamic Financial Analysis
Dynamic Financial Analysis (DFA) is a simulation technique that looks at a reinsurer’s risks holistically by correlating assets and liabilities in a single simulation. With the advent of regulatory regimes like Solvency II, systems for Dynamic Financial Analysis have become essential tools for insurance and reinsurance companies.
This project explores both the current state of the art in DFA systems and a number of associated statistical and computing questions. Activities include:
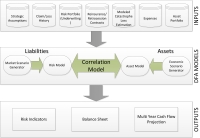 Collection and review of the literature on Dynamic Financial Analysis and evaluation of existing open-source and commercial DFA systems with the aim of understanding the current state of the art and determining what are the key open questions.
Collection and review of the literature on Dynamic Financial Analysis and evaluation of existing open-source and commercial DFA systems with the aim of understanding the current state of the art and determining what are the key open questions.- Investigation of some key open questions from a statistical perspective through the creation of R based prototypes. These prototypes explore questions such as
- How many simulation trials are sufficient? Bootstrapping and other
statistical techniques can be used to quantify the accuracy of
simulation results? - Often correlation between risk sources must be modeled. How
sensitive are the model results to the correlation parameters? Which
correlation coefficients have the biggest impact and warrant further
investigation? - To what degree is Catastrophe Risk (or Underwriting risk) correlated
with Investment Risk? - What are appropriate methods for inducing correlation? If a copula
is used to induce correlation, then the literature suggests that a
T-copula is preferable to a Gauss copula due to the t-Copula’s
emphasis on tail dependence.
- How many simulation trials are sufficient? Bootstrapping and other
Big Data Risk Analytics

Risk management companies are gradually becoming data rich. Not only are they collecting more about their individual exposures but the amount of data on hazards, structural vulnerabilities, and individual financial terms and contracts is steadily increasing both in terms of coverage and detail. In addition to exposure data, event based risk analysis models generate massive data sets. In order to manage this deluge of data, aggregation has been aggressively used. Aggregation helps greatly to reduce data volumes while still giving the risk manager or analyst the big picture, but it discards much of the fine detail.
In this project we explore the following questions:
- How can "Big Data" techniques, developed in the context of web-scale analytics, be put to effective use in risk analysis?
- What classes of analytical questions could be answered using big data techniques that can't be answered with current aggregation-based approaches?
- What are the right hardware and software architectures to support big data risk analytics? Are we best served by large in-memory systems, for example SAP HANA, or file based systems like Hadoop?
- What is the right data warehouse structure?
Previous Research Projects
Global Earthquake
Over the last twenty years, Catastrophe Modelling Systems, which seek to quantify expected losses due to catastrophic events, have become a mature technology widely used in the insurance and reinsurance settings. These systems typically focus on pre-event analysis. For example, given a collection of 1 million buildings in Japan what is the expected maximum probable loss due to earthquake activity over a one year period. Pre-event catastrophe models are built using a stochastic event catalog to represent a sample of possible future events and a set of three sub-models:

- A Hazard Model which determines the degree of the hazard (i.e. ground shaking),
- A Vulnerability Model which determines the degree of damage to buildings given the hazard, and
- A Loss Model which estimates the level of financial losses.
More recently, with the expansion of sensor networks and development of communication technologies hazard models have been developed that can produce timely evaluation of hazard in near real-time.
In this project, we explore how real-time hazard models can be married to techniques developed for pre-event catastrophe modelling of vulnerability and loss to generate complete post-event analysis in the hours, days and weeks immediately following
major events. As part of this project, we have designed and implemented an Automated Post-Event Earthquake Loss Estimation and Visualization (APE-ELEV) system for real-time estimation and visualization of losses incurred due to earthquakes. Since immediately post event, data is often available from multiple disparate sources, a geo-browser is described that assists users to integrate and visualize hazard, exposure and loss data.
Physical Storm Surge Prediction for LiveCat Hurricane Models
Unlike earthquakes, we can often see hurricanes coming. A storm spins up off the horn of Africa and heads west across the Atlantic with weather forecasters and the National Hurricane Center tracking its every step. This situation gives rise to a special class of Catastrophe Models called LiveCat models. These models use the known physical parameters of the live storm as a starting place from which to generate a mini stochastic event catalog that tries to capture possible ways the event may unfold and their statistical likelihood. Such models are particularly useful in the spot insurance markets that may arise in the 12-48 hours before a major storm makes landfall.
LiveCat models must be fast to initialize and run if they are going to be truly useful in livecat scenarios. So there is a trade-off to be made between model fidelity, the degree to which a model or simulation reproduces the state and behavior of a real world system, and model performance or run time.

In this project, we explore the design of physically based storm surge models. We are interested in the question "Is there a storm surge modeling methodology that is physically based, accounts for bathymetry, history of wind direction and strength, and tides, uses only publicly available global data, and is practical and fast?"
We have been developing a methodology for forecasting maps of both 1) the probability of exceeding a given sea level during a hurricane, and 2) the exceedance level for a given exceedance probability based on an ensemble of forecasts. The work involves a new approach for down scaling from the large to local scale in a computationally efficient manner. This is joint work with Dr. Keith Thompson, Canada Research Chair in Marine Prediction and Environmental Statistics.