Artifacts
As a research team, we produce a variety of artifacts such as tools, datasets, and repositories useful for other researchers and practitioners. This page consolidates all our offerings in one place for better dissemination.
Table of contents
Tools
1. Designite
Designite is a code quality assessment tool for C# and Java. It offers various features to help identify code smells contributing to technical debt and improve the quality of the analyzed software system.
Key features
- Detects 7 architecture smells
- Detects 20 design smells
- Detects 11 implementation smells
- Detects 4 testability smells and 8 test smells
- Computes various object-oriented code quality metrics
- Supports multi-commit analysis (only DesigniteJava)
- Provides smell trend analysis of Git repositories (only Designite)
- Many visualization aids including (smell) treemap, and (smell) sunburst (only Designite)
- Detects code duplication (only Designite)
- Allows customization of analysis
Visit the tool's website for more details. You may download the latest version of the tool from the download page. Software engineering researchers may request a free fully-functional Academic license of this tool.
2. CodeGreen
CodeGreen is a command-line interface (CLI) tool that profiles the energy consumption of TensorFlow API calls. It leverages our previously developed FECoM framework to instrument TensorFlow code and measure the energy usage of API calls.
Key features
- Automatically instruments TensorFlow code to isolate and measure energy consumption of API calls
- Captures relevant metadata such as function arguments, keywords, objects and their sizes, execution times, and code line numbers
- Utilizes hardware performance counters to precisely measure energy consumption from CPU, GPU, and RAM during API execution
- Provides an easy-to-use CLI interface for accessible energy profiling workflows
- Enhances the underlying FECoM framework with expanded argument type support, GitHub metadata capture, and streamlined setup via pip
Visit the CodeGreen PYPI for installation and CodeGreen repository for replication package.
Datasets
1. DACOS
DACOS is a manually annotated dataset containing $10,267$ annotations for $5,192$ code snippets that takes into consideration the subjective nature of code smells. The code smells are: multifaceted abstraction, complex method, and long parameter list.
DACOS was created in two phases. In the first phase, we identify the code snippets that are potentially subjective by determining the thresholds of metrics used to detect a smell (e.g. LCOM). The second phase collects annotations for potentially subjective snippets. We also offer an extended dataset DACOSX that includes definitely benign and definitely smelly snippets by using the thresholds
identified in the first phase.
Dataset description
| Dataset | Code smell | # Annotations | # Samples |
|---|---|---|---|
| Complex method | 4,349 | 2,197 | |
| DACOS | Long parameter list | 3,221 | 1,634 |
| Multifaceted abstraction | 2,697 | 1,361 | |
| Total | 10,267 | 5,192 | |
| Complex method | - | 94,489 | |
| DACOSX | Long parameter list | - | 93,442 |
| Multifaceted abstraction | - | 19,674 | |
| Total | - | 207,605 |
For more details on the methodology used to generate this dataset, please refer to our work published in MSR'23.
The dataset is available on Zenodo: ![]()
2. Candidates for extract method refactoring
The dataset consists of positive and negative case methods for Extract Method refactoring for selected GitHub repositories.
Each sample format -
{
"repo_name": "...",
"repo_url": "...",
"positive_case_methods": ["...", "...", ...],
"negative_case_methods": ["...", "...", ...]
}
Repo - How extract method identification is performed using this dataset.
For more details on the methodology, please refer to our work published in ICSME'23. (preprint / IEEE)
The dataset is available on Zenodo: ![]()
3. Greenlight
Greenlight is a comprehensive dataset containing fine-grained energy consumption measurements for 1,284 TensorFlow API calls. It was curated using our CodeGreen CLI tool.
Dataset description
The Greenlight dataset provides the following information for each TensorFlow API call:
- Energy consumption
- Execution time
- Timestamps
- Power draw time series
- Input argument details (size, keywords)
- Hardware temperature readings
- Associated Git commit metadata (date, hash)
- Source code location of the API call
JSON schema of the dataset is as follows:
{ "tensorflow.io.TFRecordWriter.close()":
{
"energy_data": {
"cpu": "Power draw time series",
"ram": "Power draw time series",
"gpu": "Power draw and Temp. time series",
},
"times": {
"start_time_execution": "Execution start time",
"end_time_execution": "Execution end time",
"start_time_perf": "perf start time",
"end_time_perf": "perf end time",
"sys_start_time_perf": "erf sys start time",
"start_time_nvidia": "nvidia-smi start time",
"end_time_nvidia": "nvidia-smi end time",
"sys_start_time_nvidia": "nvidia sys start time",
"begin_stable_check_time": "stability time stamp",
"begin_temperature_check_time":"temp. time stamp"
},
"cpu_temperatures": "Temperature time series",
"settings": {
"max_wait_s": 120,
"wait_after_run_s": 30,
"wait_per_stable_check_loop_s": 20,
"tolerance": 0,
"measurement_interval_s": 0.5,
"cpu_std_to_mean": 0.03,
"ram_std_to_mean": 0.03,
"gpu_std_to_mean": 0.01,
"check_last_n_points": 20,
"cpu_max_temp": 55,
"gpu_max_temp": 40,
"cpu_temperature_interval_s": 1
},
"input_sizes": {
"args_size": "Size in bytes",
"kwargs_size": "Size in bytes",
"object_size": "Size in bytes"
},
"project_metadata": {
"project_name": "Repo name",
"project_repository": "https://github.com/...",
"project_owner": "owner",
"project_branch": "master",
"project_commit": "Commit hash",
"project_commit_date": "Time stamp",
"script_path": "/home/...",
"api_call_line": "Line number"
}
}
}
The dataset captures energy profiles across a diverse set of projects spanning domains like computer vision, natural language processing, and distributed computing.
For more details on the dataset construction methodology, please refer to our paper. (preprint)
The Greenlight dataset is available on Zenodo: ![]()
Repositories
1. Extract Method Identification
A self-supervised autoencoder approach to predict extract method refactoring candidates. It outperforms state-of-the-art by 30% in F1 score.
Approach
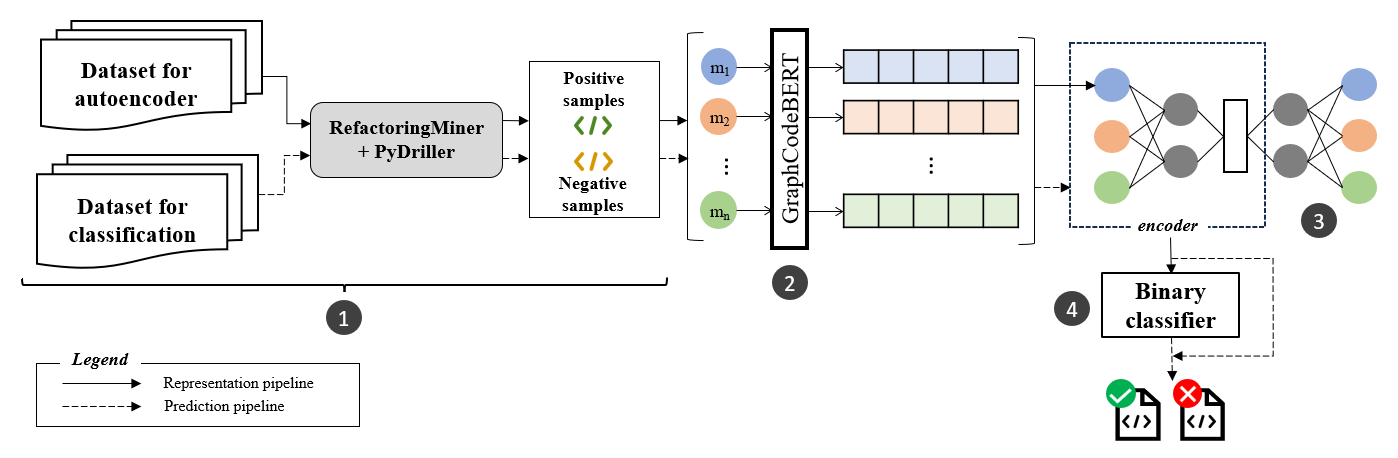
For more details on the methodology, please refer to our work published in ICSME'23. (preprint / IEEE)
Dataset used: Candidates for extract method refactoring
2. FECoM
FECoM (Fine-grained Energy Consumption Meter) is a framework for measuring the energy consumption of individual API calls in deep learning libraries at a fine-grained level (currently supports Tensorflow). It combines static analysis with dynamic instrumentation to isolate API invocations and measure their energy footprint. The FECoM Framework repository contains the source code, documentation, and usage examples for our Framework for Automated Energy Profiling of Tensorflow APIs.
Key features
- Static analysis for API usage pattern identification and argument extraction
- Dynamic code instrumentation for targeted energy measurement of API calls
- Precise energy readings using Intel RAPL (Running Average Power Limit) interface
- Support for CPU and GPU based energy measurements
- Extensible architecture to add support for new deep learning frameworks
FECOM enables researchers to study the energy characteristics of deep learning APIs and developers to optimize their code for energy efficiency.
Key components of the Framework:
- Static Analyzer: Identifies API usage patterns and extracts API call arguments
- Dynamic Instrumentor: Injects energy measurement probes around API invocations
- Energy Profiler: Reads energy consumption values from hardware counters
- Results Aggregator: Processes raw readings and generates energy profiles
Visit the FECoM repository for more details on the framework architecture and usage instructions.
For more details on the framework methodology, please refer to our paper. (preprint)
3. COMET
COMET (Context-Aware Commit Message Generation) is a novel approach that generates high-quality commit messages by capturing the context of code changes using a graph-based representation. The COMET repository provides the source code, pre-trained models, and usage examples for our commit message generation framework.
Key features
- Utilizes a graph-based representation called Delta Graph to effectively capture the context of code changes
- Leverages a transformer-based model to generate informative commit messages
- Includes a customizable quality assurance module to identify optimal messages and mitigate subjectivity
- Outperforms state-of-the-art techniques and popular language models like GPT-3.5 and GPT-4 in commit message generation
- Provides implications for researchers, tool developers, and software developers to generate context-aware commit messages
Key components of the Framework:
- Delta Graph Module: Converts code changes into a graph-based representation capturing the change context
- Transformer-based Generator: Fine-tuned model that generates commit messages from the Delta Graph representation
- Quality Assurance Module: Ranks and selects the best generated message based on user-defined criteria
- Pre-processing Module: Filters training dataset to ensure high-quality commit messages are used for model training
The COMET repository includes the complete source code, pre-trained models, and detailed instructions for using and extending the framework. Researchers and developers can utilize COMET to generate context-aware commit messages and explore the application of the Delta Graph technique in related domains like code review summarization.
Visit the COMET repository for more details on the framework architecture and usage instructions.
For more details on the COMET framework and its performance evaluation, please refer to our paper. (preprint)