--- config: look: handDrawn theme: neutral --- flowchart LR A[Clinical problem] --> B[Target / label] B --> C[Data] C --> D[Model] D --> E[Metric] E --> F[Claim] F --> G[Decision in practice]
What the Paper Doesn’t Tell You
Scientific Frames for Evaluating AI in Clinical Practice · UBC Research Day · April 17, 2026
The algorithm that rationed care by accident
- Picture a hospital using an algorithm to decide who gets extra care.
- Two patients are equally sick.
- The model ranks one ‘high risk’ and the other ‘low risk’, and only one gets help.

The algorithm that rationed care by accident
- Researchers later discovered the model wasn’t predicting sickness at all.
- It was predicting future healthcare cost.
- Because cost reflects access and spending patterns, not just illness, the algorithm systematically underrated Black patients.
- Fixing the target would have increased the share of Black patients flagged for extra help from 17.7% to 46.5% (Obermeyer et al. 2019)
Case 2: Pneumonia risk

Tip
OK, good. Risk of pneumonia increases with age.
Important
Uh oh, bad. Risk of pneumonia decreases if you have asthma??
Note
- It turns out, in the data, patients with a history of asthma who presented with pneumonia usually were admitted not only to the hospital but directly to the ICU.
- Author’s solution: remove the term, or ask a human to redraw the graph.
- This assumes the channel effect (or bias) is even recognized in the first place.
🕵️♀️ How does bias enter?
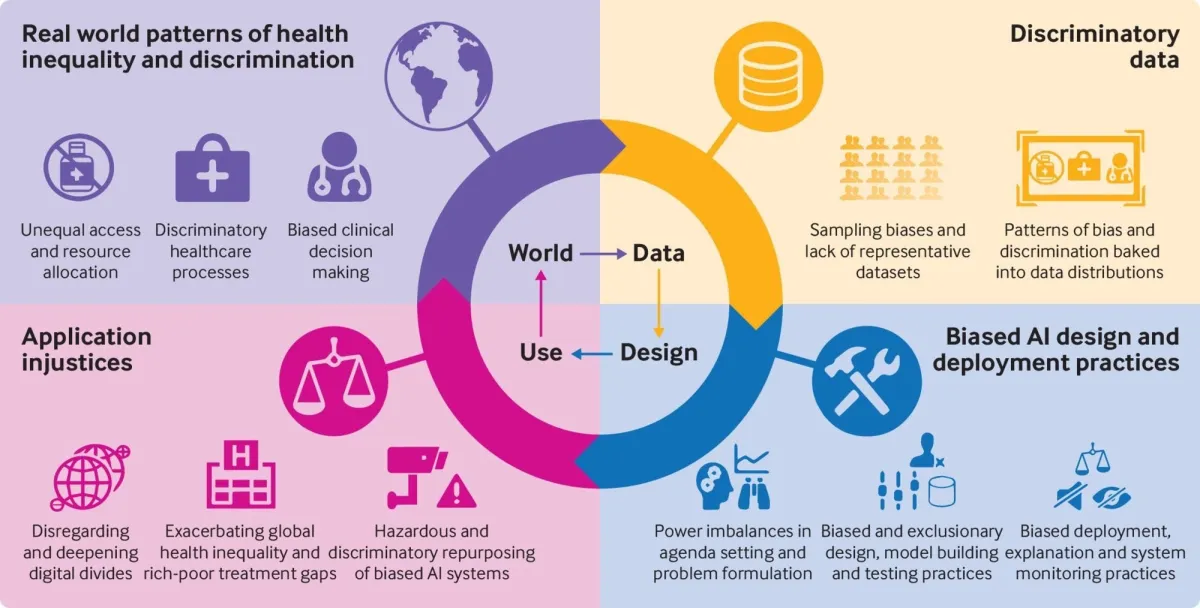
From Fusar-Poli et al. (2022).
- Data bias — the training set reflects historical inequities.
- Model/design bias — proxy features silently encode protected attributes; loss functions optimise globally, ignoring subgroup harm.
- Feedback loops — biased decisions produce biased new data, amplifying the problem over time.
Not all bias is illegal or even (always) wrong — a spam filter should be biased against phishing emails, e.g..
The hard question: which systematic errors are acceptable, for whom, and who decides?
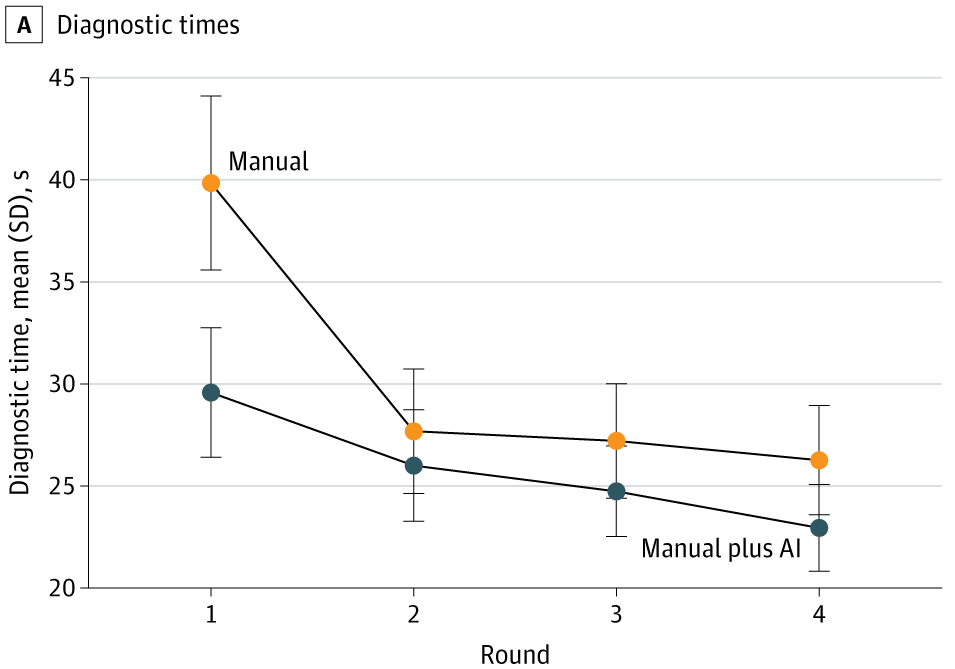
Case study 1: AMD workflow paper
A 2025 age-related macular degeneration study in JAMA Network Open is useful because it goes beyond a single held-out test set (Chen et al. 2025).
Findings (not just ‘accuracy’, not just once):
- AI assistance improved accuracy for 23 of 24 clinicians
- mean F1 increased from 37.71 to 45.52
- AI assistance saved roughly 10 seconds per patient initially
- after further model development, external performance improved
- but clinician + AI did not always outperform AI alone (Chen et al. 2025)
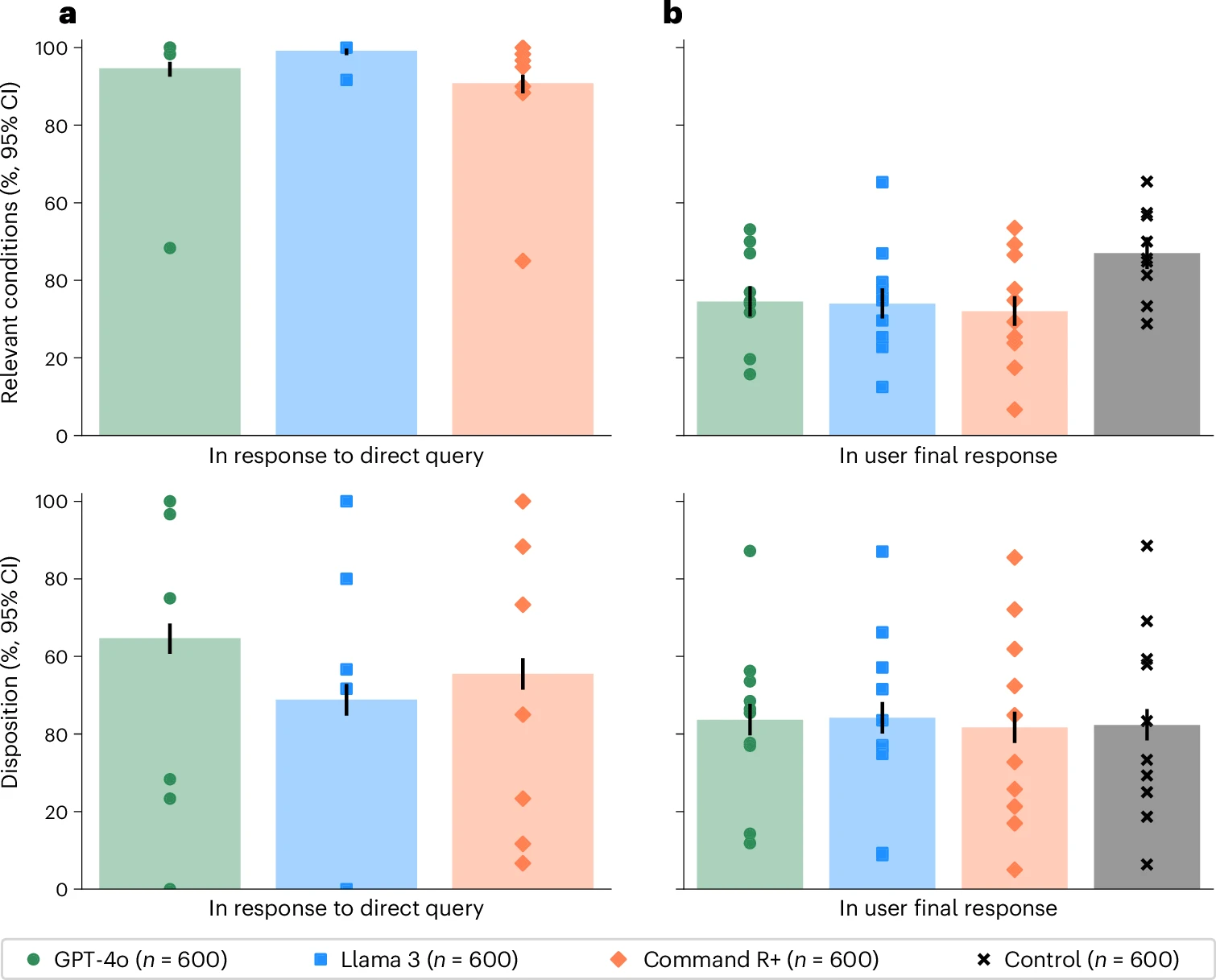
Case study 2: LLMs + public medical advice
A 2026 Nature Medicine randomized study tested whether LLMs help members of the public make medical decisions in realistic scenarios (Bean et al. 2026).
- Tested alone, the models looked very strong:
- 94.9% correct for condition identification
- 56.3% correct for disposition
- But people using those same models performed rather poorly.
- fewer than 34.5% identified the relevant condition
- fewer than 44.2% got the disposition right (Bean et al. 2026)
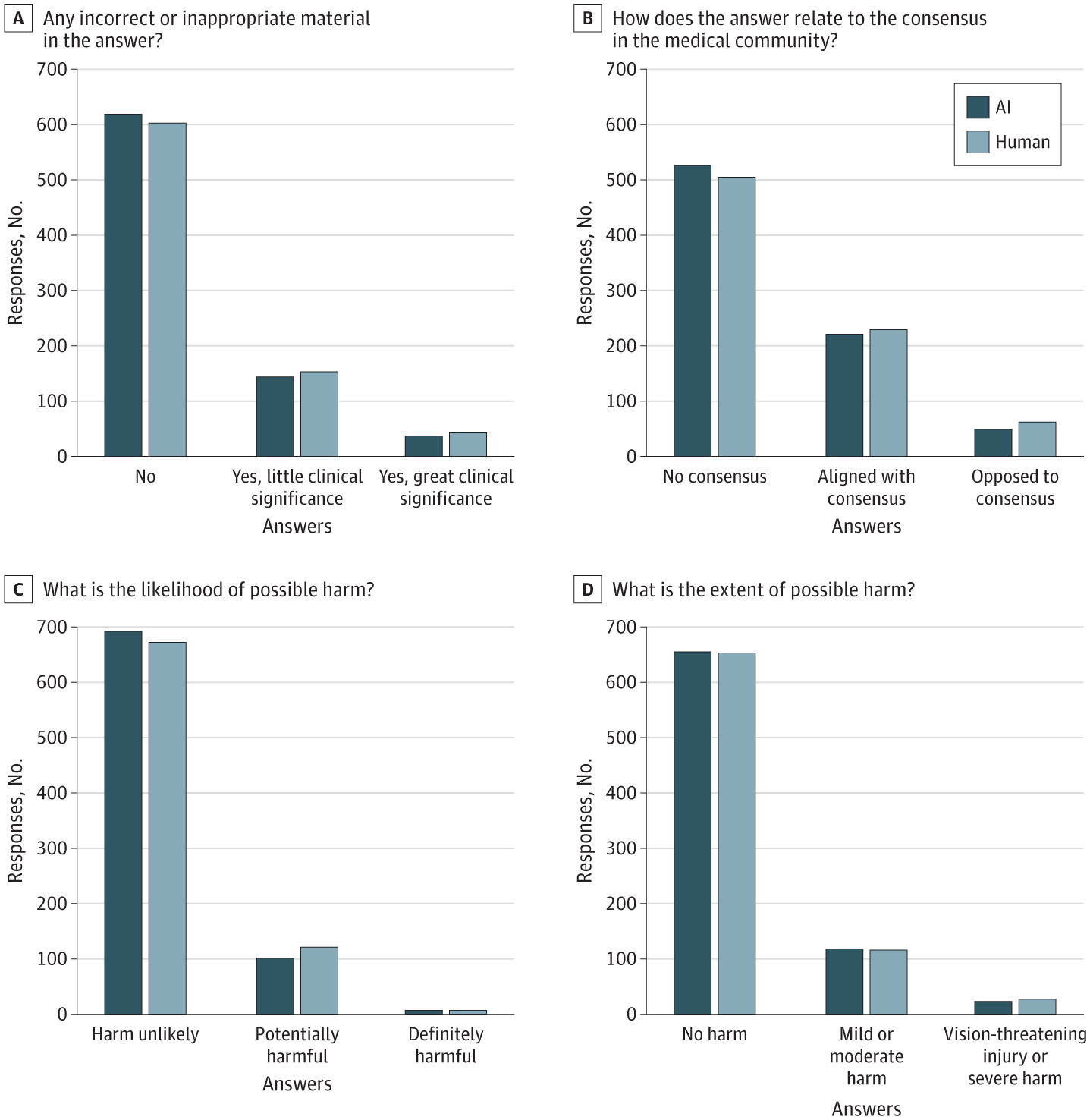
Case study 3: Chatbot vs humans
Bernstein et al. (2023) compared ophthalmologists to a chatbot on online eye-care questions. Reviewers rated the quality of many answers similarly, and distinguished human from chatbot responses with only 61% accuracy.
Interesting, but still ask:
- forum questions or real clinic?
- no liability, or real liability?
- no chart context, or full chart context?
- no longitudinal follow-up, or actual follow-up?