The Sisyphean Cycle of Hype and Fear in Medical AI
UBC Research Day · April 17, 2026
Disclaimer
Except only tangentially, I have not worked in AI + ophthalmology.
I have worked in AI + surgery, which uses similar techniques (in academia, industry, and standards) and I currently work in AI Safety, which flavours some of this talk.
The benchmark mistake
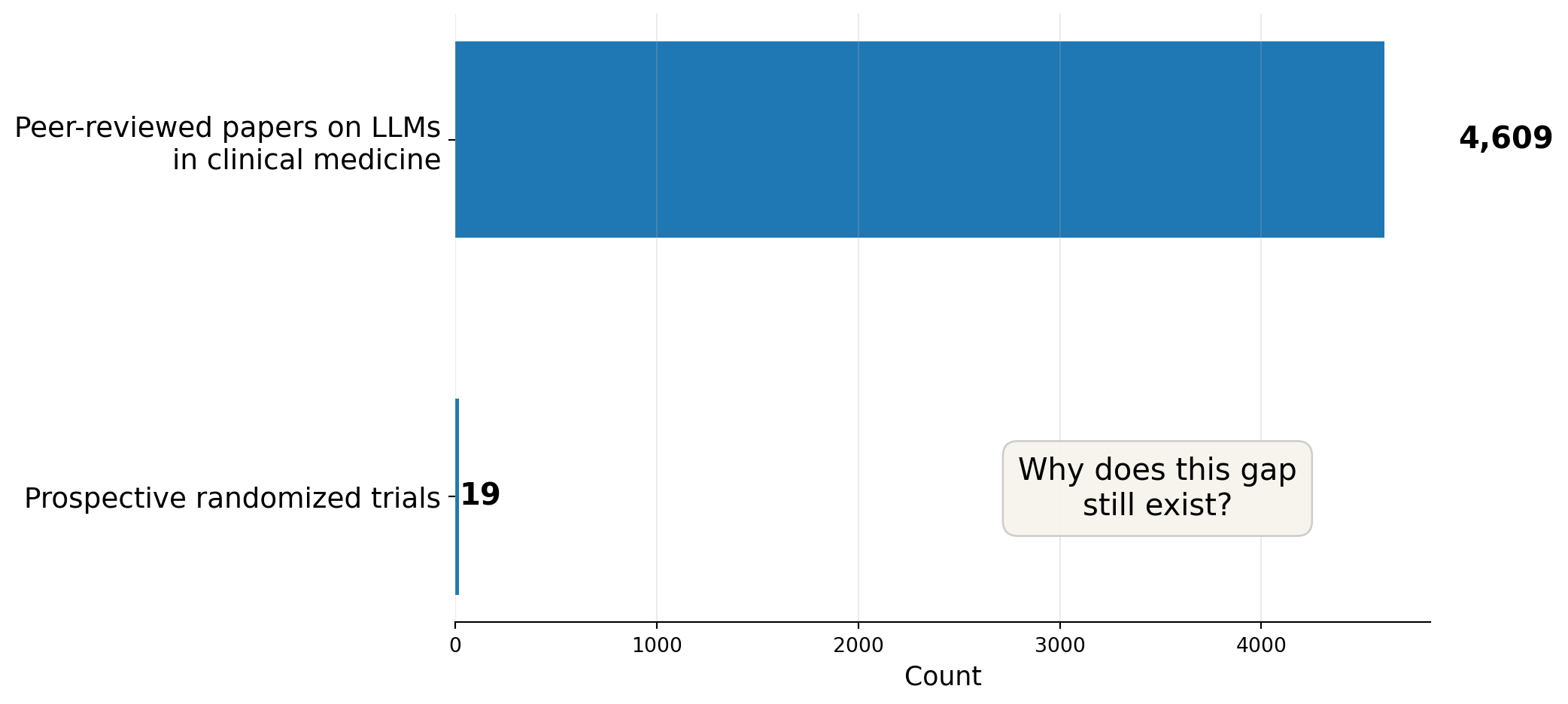
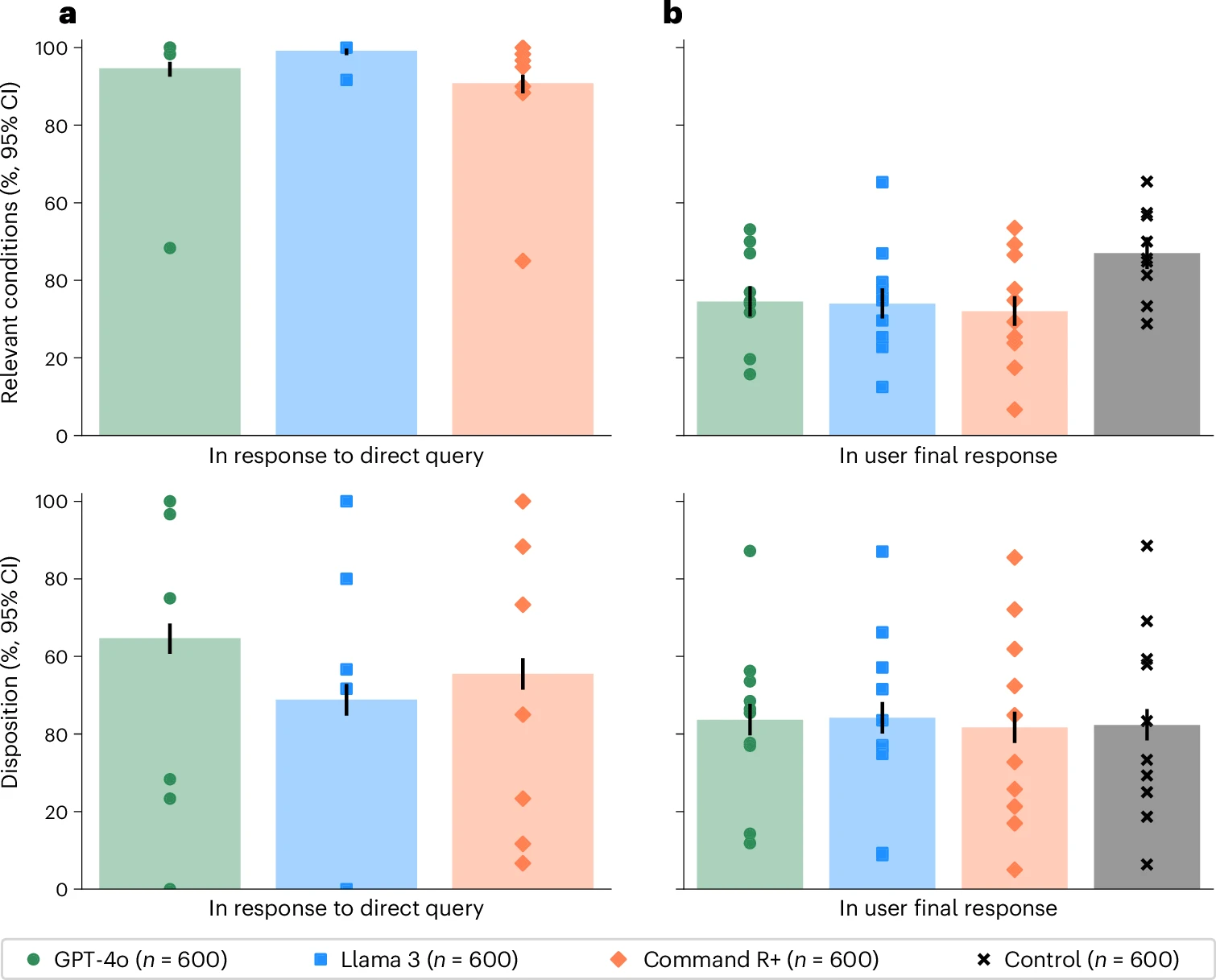
A 2026 Nature Medicine randomized study tested whether LLMs actually help members of the public make medical decisions in realistic scenarios (Bean et al. 2026).
- Tested alone, the models looked very strong:
- 94.9% correct for condition identification
- 56.3% correct for disposition
- But people using those same models performed rather poorly.
- fewer than 34.5% identified the relevant condition
- fewer than 44.2% got the disposition right (Bean et al. 2026)
AI in Ophthalmology
A 2026 JAMA Ophthalmology “Eye on AI” theme explicitly argued that ophthalmology is one of the places where AI may be transformative, especially through image analysis and natural language processing (Liu and Bressler 2026).
AI in ophthalmology makes sense:
- visually rich data,
- specialist bottlenecks,
- screening needs,
- and increasingly digital workflows.
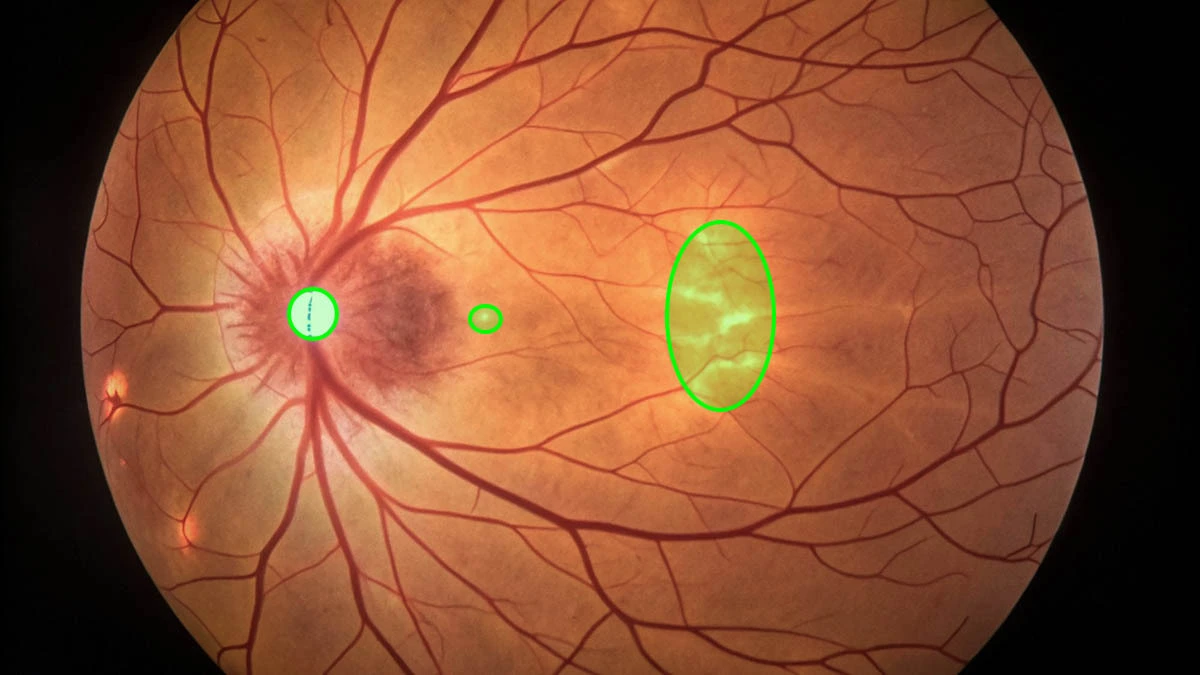
A recent ophthalmology example
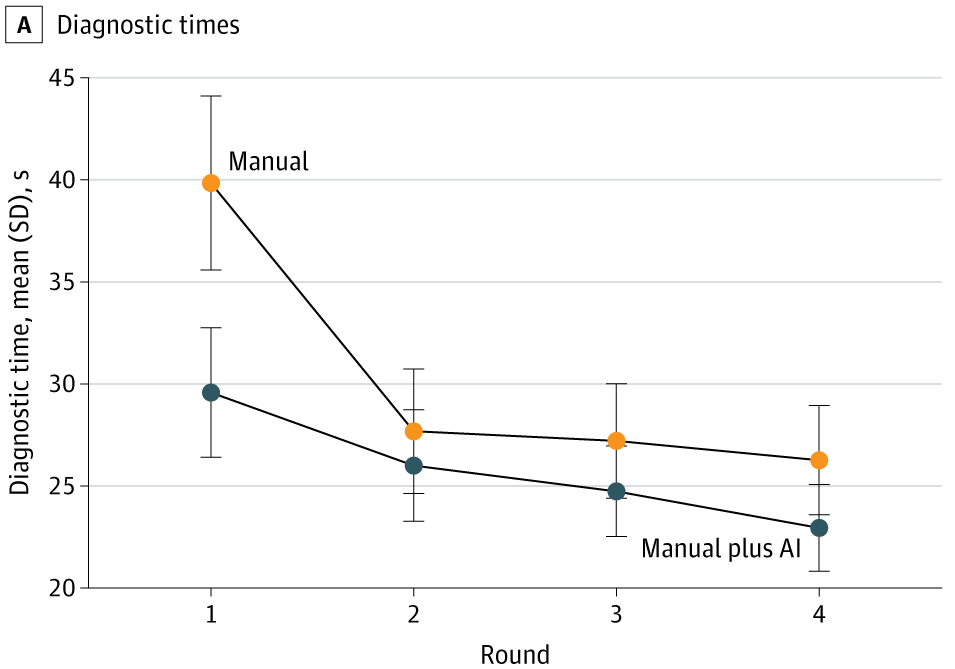
A 2025 JAMA Network Open study on age-related macular degeneration built an AI-assisted workflow and evaluated clinicians across four rounds, alternating manual diagnosis and diagnosis with AI assistance (Q. Chen et al. 2025).
Findings (not just ‘accuracy’, not just once):
- AI assistance improved accuracy for 23 of 24 clinicians
- mean F1 increased from 37.71 to 45.52
- AI assistance saved roughly 10 seconds per patient initially
- after further model development, external performance improved
- but clinician + AI did not always outperform AI alone (Q. Chen et al. 2025)
A useful evidence ladder for medical AI
From weakest to strongest:
- benchmark or exam-style performance
- retrospective validation
- temporal or external validation
- human-AI comparative workflow study
- silent prospective evaluation
- live clinical trial or monitored deployment
Most arguments in public discourse are made as if stage 1 or 2 already implies stage 6.

The intervention-history mistake
Note
Another canonical example: the pneumonia risk model of Caruana et al. (2015).
The model appeared to learn that asthma lowered pneumonia mortality risk.

What the model had learned was a channel effect: patients with asthma and pneumonia were more likely to be treated aggressively, including ICU admission.
So the model captured part of the care pathway, not just the disease process.
Bias is not one thing
When people say “bias” in medical AI, they often compress very different problems into one word.
At least four distinct layers matter:
- representation bias
who is in the data? - label bias
what exactly do labels encode? - deployment bias
how does the system change behaviour? - adoption bias
who gets access to the tool, and under what conditions?

Suggestions
Khattak et al. (2025) provide an MLHOps checklist for clinical ML to be deployable, monitorable, and maintainable by:
- preparing the data
- engineering the pipeline
- deploying with the workflow in mind
- monitoring for drift
- updating deliberately
- governing for bias, privacy, and trust
Choose local, free-range, organic AI!

