Responsible AI
What is standard, and what should be
2025-12-10
A clinical vignette
Consider a widely discussed study of mortality risk prediction using “intelligible” models and patients presenting with pneumonia (Caruana et al. 2015).
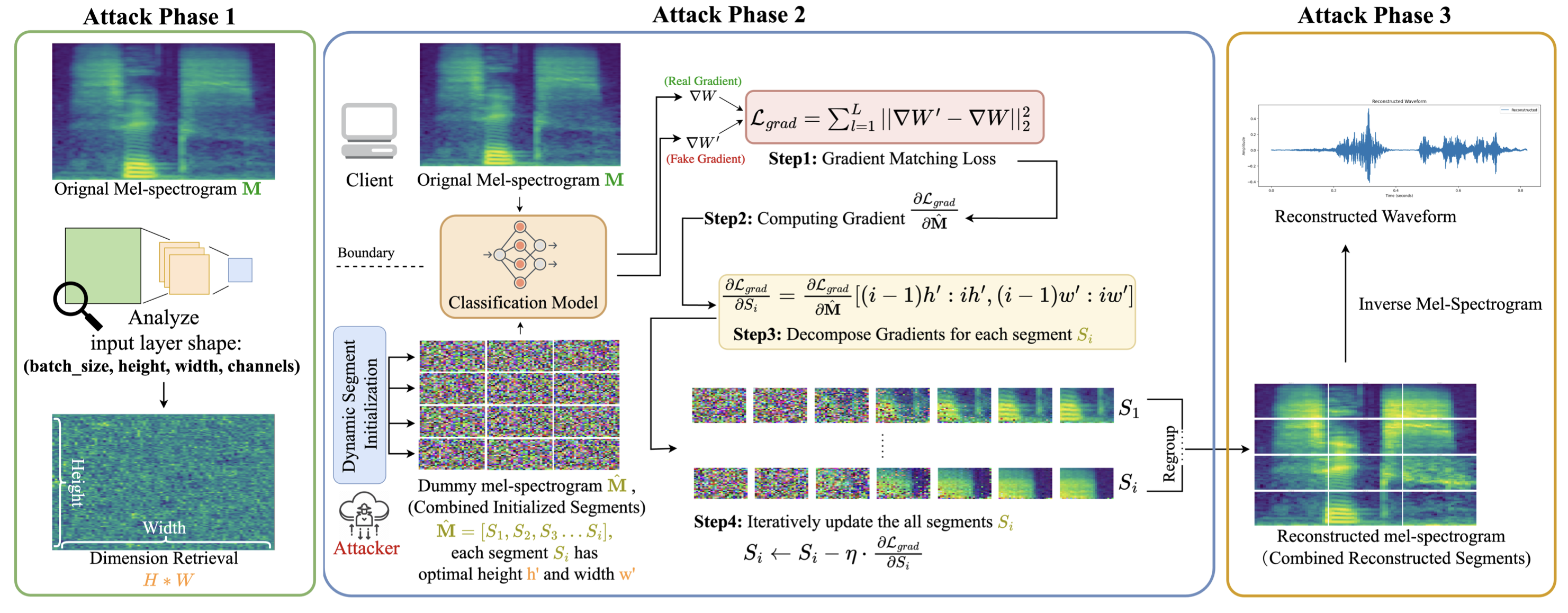
- This uses a generalized additive model with pairwise interactions (GA2M), so clinicians can see how each factor affects risk.
- 😲 Asthma appears to decrease the risk of death from pneumonia. 😲
- Clinically, this makes no sense
- 💡 In practice, patients with asthma often receive more aggressive and timely care (ICU, closer monitoring)
Explanations ≠ Truth

Note
Our pneumonia model “explains” that asthma lowers mortality risk. Is that a helpful explanation—or a red flag?
Visual Explanations
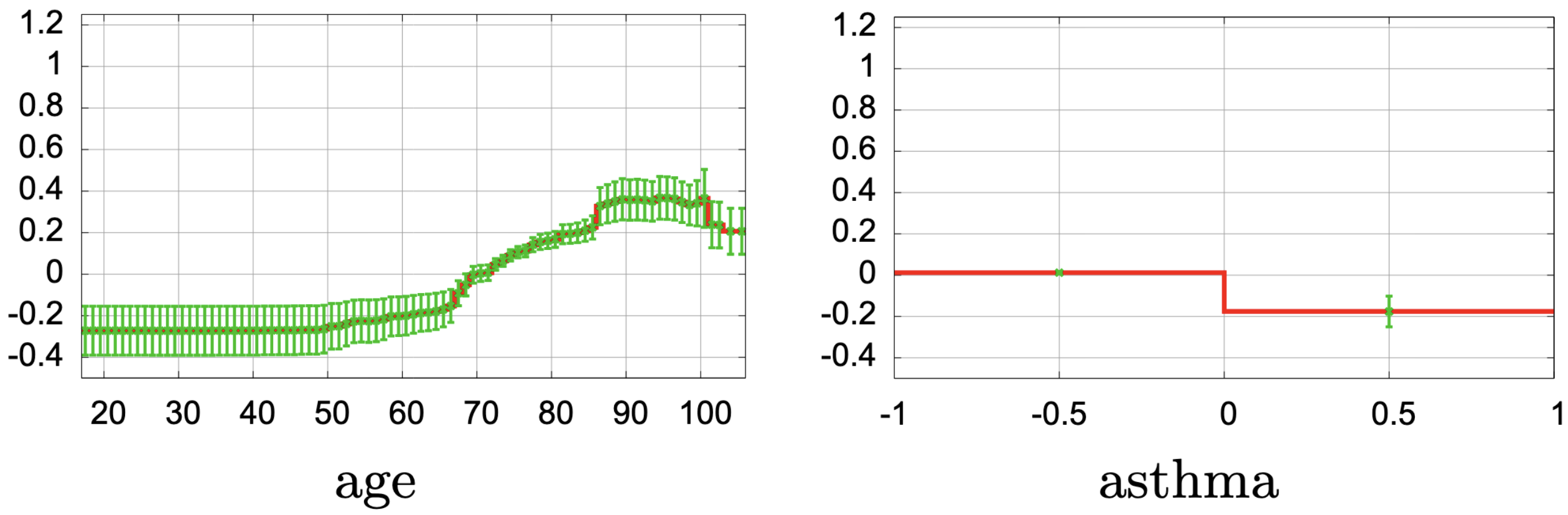
Heatmaps (for images)
From Cinà et al. (2023)
Text attention overlays

From Feng, Shaib, and Rudzicz (2020)
Explaining our pneumonia example
- Our pneumonia model outputs a risk score for each admission.
- Global explanation (GA2M curves)
- Age: risk rises sharply after ~65
- Low oxygen saturation: risk increases steeply below a threshold
- Very high temperature: risk increases
- ⚠️ Asthma: risk appears to decrease risk → a clinical red flag 🚩
- Age: risk rises sharply after ~65
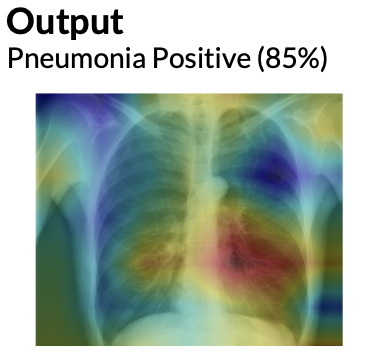
- Local explanation (e.g., SHAP)
- Shows which features push this patient’s risk up or down
- Ask: “Do these reasons match what I know about this patient?”
- Shows which features push this patient’s risk up or down
🔬 LLM self-explanations
LLMs can produce explanations along with their response, called self-explanations. (Huang et al. 2023)
For example, when analyzing the sentiment of a movie review, the model may output not only the positivity of the sentiment, but also an explanation (e.g., by listing the sentiment-laden words such as “fantastic” and “memorable” in the review). How good are these automatically generated self-explanations?
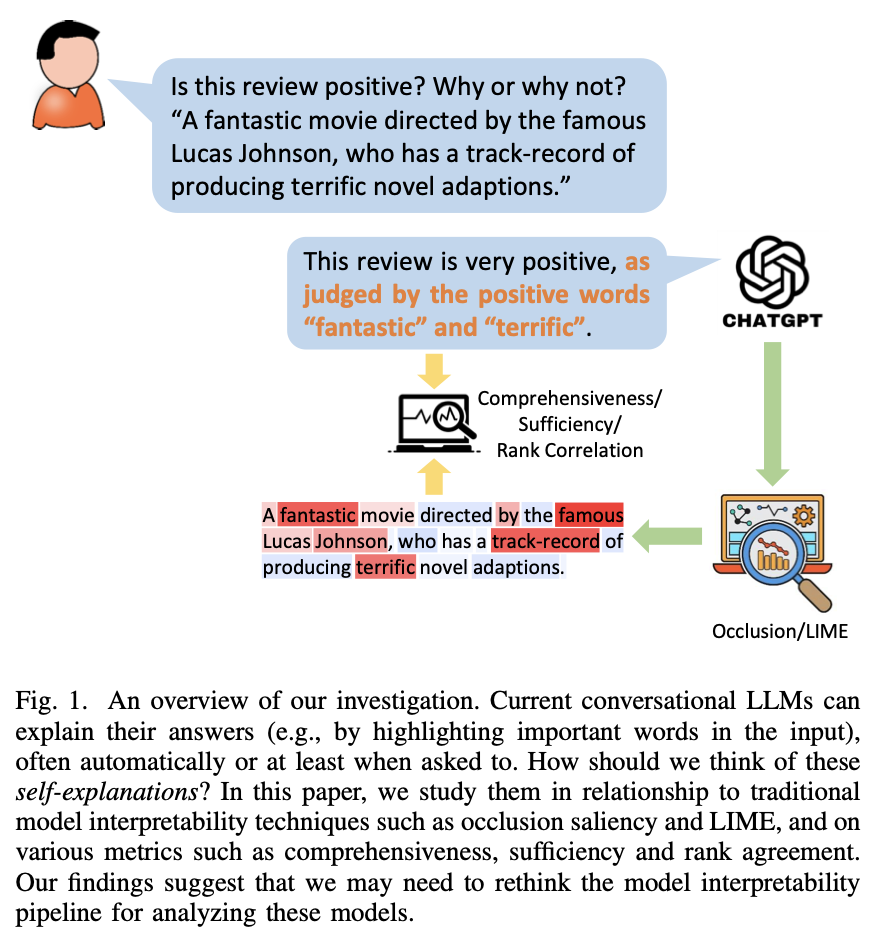
🔬 LLM self-explanations
Self-explanations cannot be assumed to be faithful without structured validation. (Madsen, Chandar, and Reddy 2024)
- LLMs can produce convincing self-explanations (e.g., chain-of-thought)
- Faithfulness varies by task, model, and explanation type
- Risk: humans tend to over-trust fluent rationales
- Solution?: Get the predicting model to produce 🔄 counterfactuals, and then run those counterfactuals.

Where bias enters the pipeline
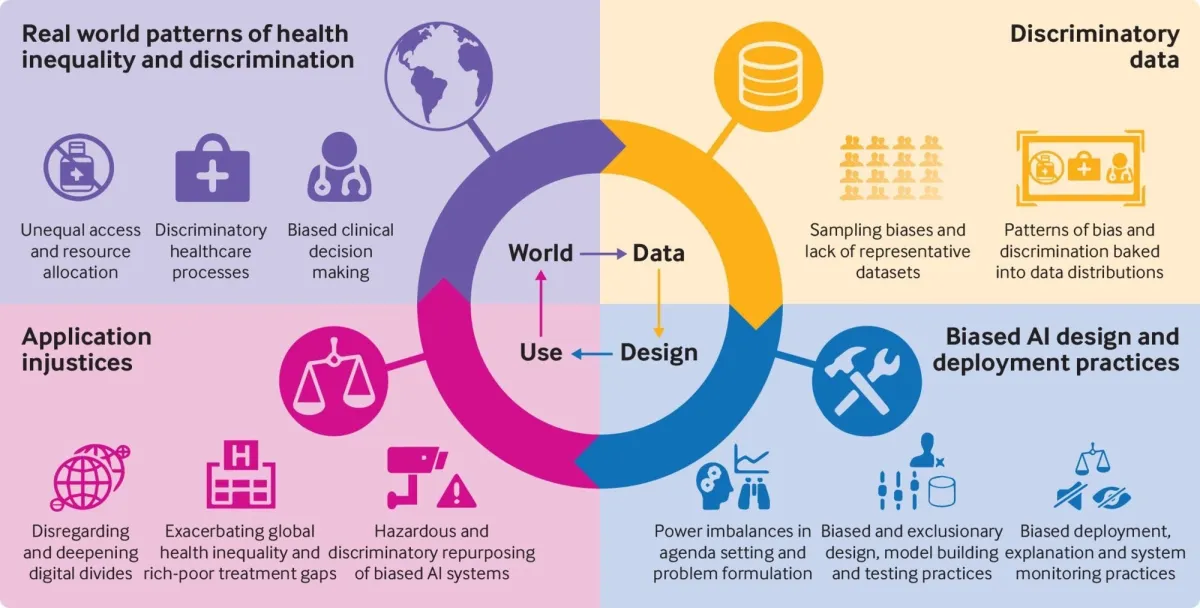
From Fusar-Poli et al. (2022).
Clinical consequences of bias
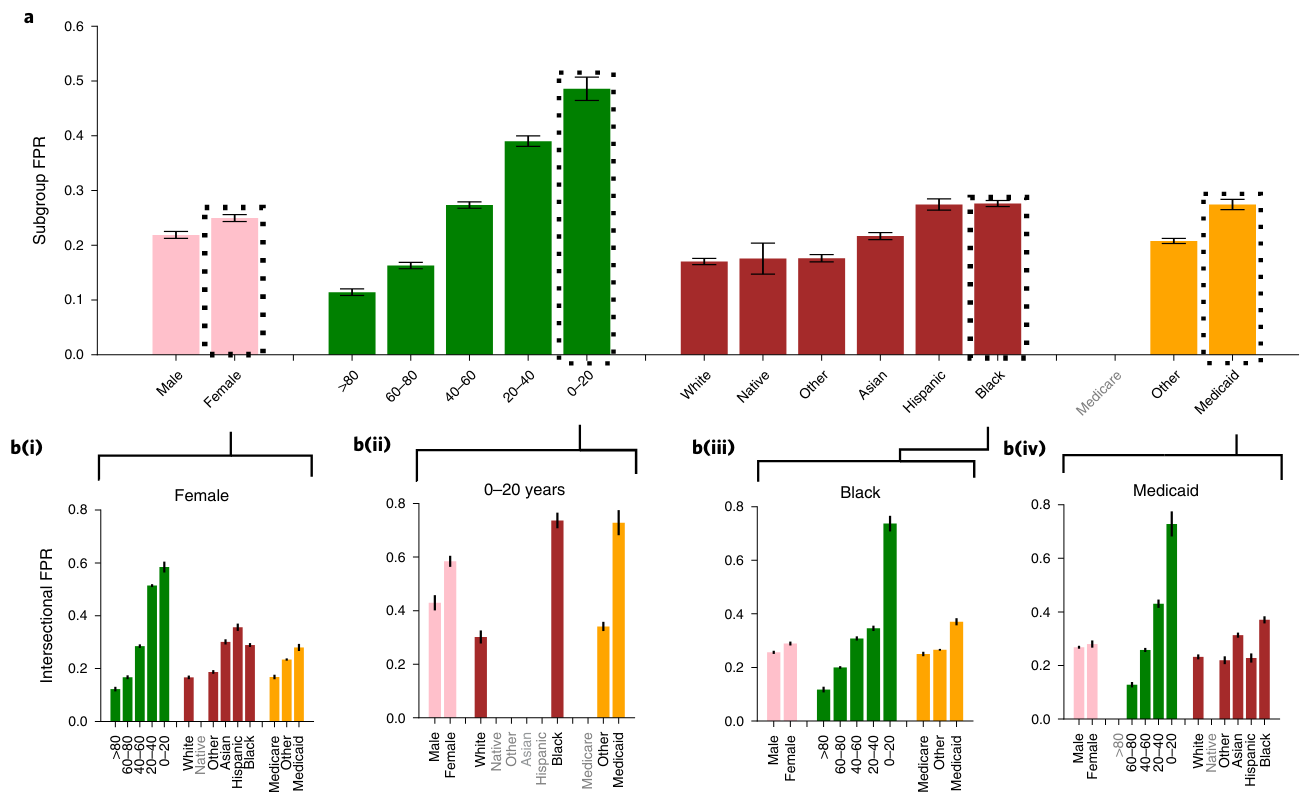
From Seyyed-Kalantari et al. (2021)
Largest underdiagnosis rates in Female, 0-20, Black, and Medicaid insurance patients.
Layered technical safeguards
No single technique is perfect.
We combine porous layers:
- \(k\)-anonymity and related de-identification methods
- Obfuscation (adding “noise” at the datum level)
- Differential Privacy (adding formal noise at the model level)
- Federated Learning (keep data local, move the model)
Note
Together, these form a privacy-preserving AI toolkit that must still be checked for fairness impacts.
2. Obfuscation
- Obfuscation: adding “noise” at the level of individual behaviour or content
- Randomized clicks, fake queries, dummy GPS traces, etc.
- Practically:
- Too permissive: re-identification is easy
- Too restrictive: clinical detail is lost
3. Differential Privacy
- 💡Solution: Don’t obfuscate the data, obfuscate the model
- Differential Privacy (DP) ensures that the probability of any output is nearly the same whether or not an individual’s data is included in the dataset.
- This guarantees indistinguishability: attackers cannot confidently tell if a specific person’s data was used.
- It accomplishes this through adding noise to the model
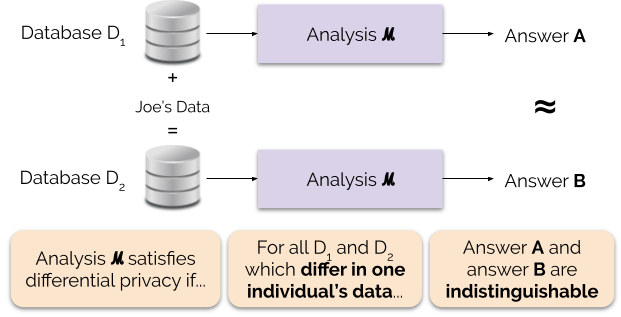
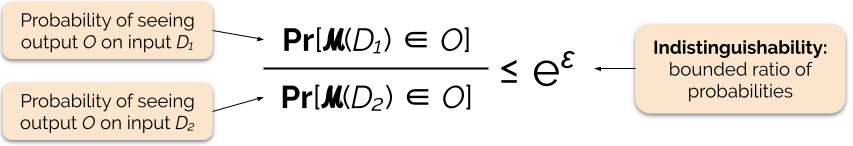
From 🔗here
4. Federated Learning
- Local training
- Each device/institution trains a model update using its own data.
- Each device/institution trains a model update using its own data.
- Aggregation
- Updates (gradients, parameters) are sent to a central server.
- The server aggregates updates into a global model.
- Updates (gradients, parameters) are sent to a central server.
- Privacy layers
- Differential Privacy: noise added to updates.
- Secure aggregation: cryptographic protocols ensure only aggregated results are visible.
- Differential Privacy: noise added to updates.
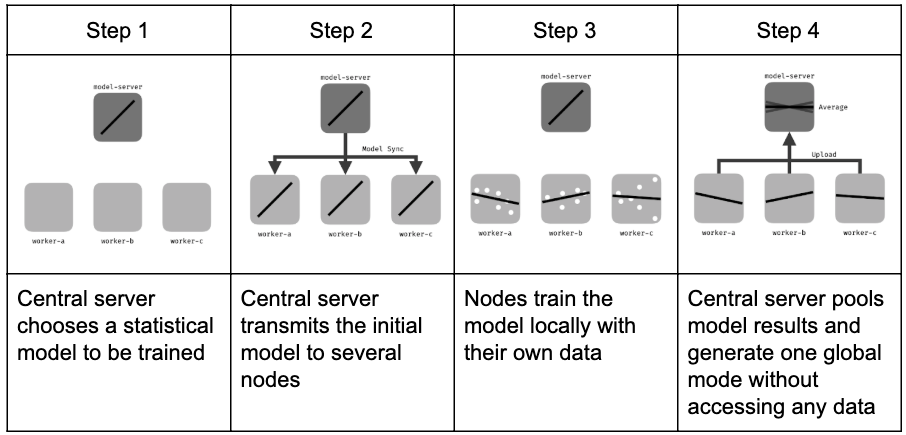 From 🔗here
From 🔗here
4. To be continued…